

——从设计模式提高开发水平01
相信大多数软件工程师的起点都是C语言,之后可能根据专注领域的不同接触了不同的面向对象编程语言,特别是Go或者Kotlin这种经常发愈发糖的语言更能够令人心情愉悦。然而不同于刚毕业的朋友们,无论是接触工程实际问题两三年的新手或者是深入实际业务的老鸟都会遇到一道厚厚的桎梏——为什么将实际业务需求转换成代码的过程总是这样蹭蹬?为什么项目总会变成一堆屎山代码?笔者在早期非常傲慢的认为这是能力孱弱的程序员们的借口和无病呻吟,直到眼睁睁看着自己投入无数精力的项目不可阻挡的变成了一坨大粪才重视起设计模式的问题。
1. 什么是设计模式——从我们如何写程序开始
在直接介入“设计模式”这个概念之前,我们首先要考虑我们书写的代码本质是什么呢?笔者并不喜欢讨论一些高深的概念和老旧的定义,因此我们不如从一个游戏切入:
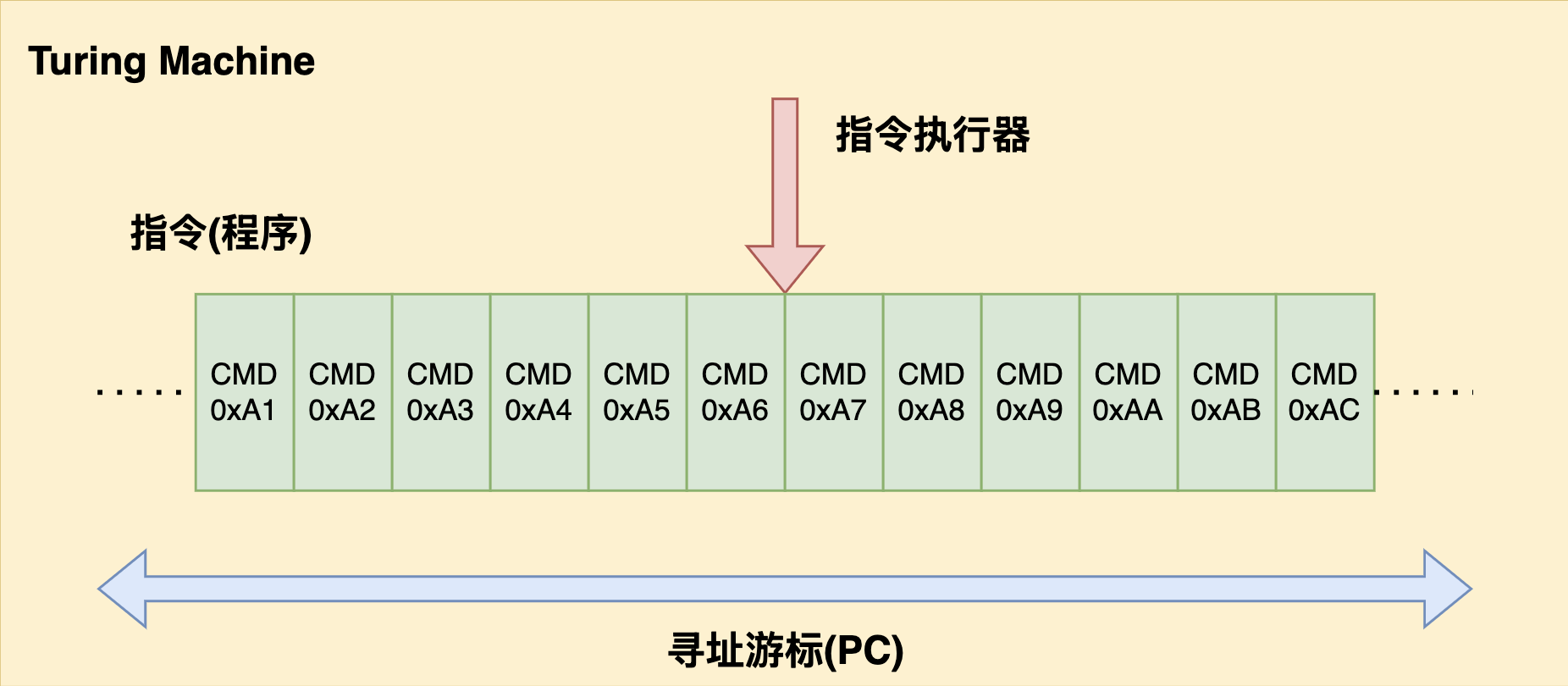
图灵机是一种概念之中的理想计算机,主要包括能够相互作用的三部分:
能够读取并且执行指令的指令执行器,对应于CPU之中的ALU,Controller等部分
一大堆可执行指令的集合,也就是我们所说的程序(Program),也就是我们编写代码的最终运行形式
能够驱动指令切换的部件,这样执行器才能够执行不同的指令——当然这些指令包括跳转到其他指令执行,这也就是我们所说的程序计数器指针(Program Counter)
以ARM架构的Thumb指令集为例,我们现在要计算5+3的结果是多少,该如何写呢?
0010 0000 0000 0101
0010 0001 0000 0011
0001 1000 0100 0010我们只要将以上的0/1代表的电平写入数字电路就成功啦!屁嘞,这谁看得懂啊,于是我们将这些数字转换为人类更加好记忆的字符串就得到了汇编语言,虽然它仍然面目可憎,但是总归更好令人接受:
MOV R0, #5 ;将立即数5存入寄存器R0
MOV R1, #3 ;将立即数3存入寄存器R1
ADD R2, R0, R1 ;计算R0+R1并且将结果存入R2当然这其中省略了很多内容,例如我们想要实现最简单的输入提示,键盘输入,屏幕(命令行)输出功能,所需要的汇编代码根据CPU架构的不同,主板芯片组的差异,操作系统的选择会有巨量的代码以及各种各样的变例,然而这段C++代码必然能够运行:
#include<iostream>
using namespace std;
int main(){
int a,b;
cout<<"Input first number:";
cin>>a;
cout<<"Input second number:";
cin>>b;
cout<<"Result: "<<a+b<<endl;
return 0;
}虽然我们添加了更多的业务功能,有了更加易用的工具,使用了更加先进的高级语言,但是计算A+B这件事并没有发生任何改变。在这个过程之中我们究竟做了什么从0/1电平转换到C++?
我们的CPP代码运行需要编译,
<iostream>库以及操作系统接口提供了输入输出方法,离开了编译器,操作系统,支持库等等事物我们的代码不可运行,也就是说在编程过程之中我们一定会有依赖(Dependency)我们多次使用输入输出流
cin和cout,并且肉眼可见的其他实现相同功能的代码也要使用这些工具库函数,然而在这个过程之中我们并未在每次使用时重新编写源代码或者在编译时作出什么更改,也就是说我们一定需要复用(Multiplexing)虽然我们使用了三种不同的方法完成这个小任务,但是业务逻辑并未发生改变,也就是说我们保持了同一性(Homogeneity)
这样从实际问题或者说业务逻辑出发转换到可执行代码的操作就是程序员或者说软件工程师的核心任务既软件设计,也就是任何编程问题本质上都是这样一条思维逻辑:实际问题——抽象逻辑——设计转换——底层解构,而设计模式或者说绝大多数代码难题产生于抽象逻辑到底层解构这一步骤——设计转换。上到基于数学理论的算法(Alogorithm)下到简单的A+B都在面临、解决这样的问题,即转换、耦合、分解抽象和底层之间的协作和矛盾关系。然而软件工程既然被划分为工程,我们就不能够用实验室的思维去处理这样的情况,我们应当找到一种范式去可复现的、稳定的、流程化的解决问题。
Each pattern describes a problem which occurs over and over again in our environment, and then describes the core of the solution to that problem, in such a way that you can use this solution a million times over, without ever doing it the same way twice.
任何一个模式都描述了这样一个在我们的环境之中不断发生的问题,并且指明了这个问题解决方案的核心,按照这样的方法我们可以数百万次的使用这种解决方案而不需要做哪怕第二次重复劳动。
笔者无数次怀着崇敬的心情阅读这段由著名建筑设计师Christopher Wolfgang John Alexander对模式(Pattern)这一概念做的精准而美妙的定义,虽然他并非软件工程领域的泰斗然而这一伟大的意涵是驱动设计模式(Design Pattern)这一学科诞生的启示。随后,出现了本领域划时代的教科书级别的鸿篇巨著《Design Patterns: Elements of Reusable Object-Oriented Software》也就是国内众所周知的机械工业出版社出版的中文译本《设计模式:可复用面向对象软件的基础》,本书由四人共同完成,我们一般称为GoF,Gang of Four。他们在本书之中提出了米昂相对象编程的软件设计领域常用的23种数据组织范式,也就是所谓的“23种常用设计模式”。由于本书过于出名和优秀,所以我们说的“设计模式”一词通常也隐含的指代面向对象编程的设计模式。然而尽信书不如无书,在很多不使用面向对象编程的领域并非无法使用这种思想,近年来兴起的面向切面编程也是基于这些设计思想创新而成,在重构优化的代码的过程中事实上我们可以自己创建出属于自己的适合具体业务逻辑的设计模式,而千万不能拘泥于既定教条。
说了这么多其实并未切入设计模式的本质,笔者阅读这本书时也是走走停停时常放下这本书吃灰,所有的工程类学科都没有办法脱离广泛的工程实践和业务经验而单独讨论知识和方法论。这里举出几个例子来明确设计模式的意涵,我们都知道在C/C++项目之中.h 头文件应当被包含且仅被包含一次,否则就会出现链接器报错:xxx重定义/xxx已在其他代码之中声明,因此我们的头文件常见结构为:
#ifndef HEADER_NAME
#define HEADER_NAME
//header file content
#endif //HEADER_NAME看起来绝大多数的头文件都无法逃脱这种形式,那么我们可以说这是一种设计模式或者说这是一种模式么?很显然并不能,这仅仅是一种让代码正常参与链接步骤的必要格式(Format),其定义和用途具体且明确,并不具备模式的抽象性和解决方案应用过程上的普适性。那么笔者再举出一个例子,基于HAL库编写的STM32单片机的串口(非DMA)封装:
#ifndef UART_H
#define UART_H
#include "stm32f1xx_hal.h"
typedef enum {
UART_OFFLINE = 0x00,
UART_IDLE = 0x01,
UART_RECEIVING = 0x02,
UART_TRANSMITTING = 0x03,
UART_WAITING = 0x04,
UART_TIMEOUT = 0x05
} UART_Status;
typedef struct {
UART_HandleTypeDef* uart;
uint8_t* rxBuffer;
uint8_t* txBuffer;
uint16_t rxCnt;
uint8_t aRxBuffer;
uint16_t autoBreak;
uint16_t timeout;
volatile UART_Status status;
uint16_t waiting;
uint8_t (*rxComplete)(void);
void (*rxCallback)(void);
void (*preTx)(void);
void (*postTx)(void);
void (*breakCallback)(void);
void (*timeoutCallback)(void);
} UART_Port;
#endif //UART_H我们能够明确感受到,以上代码之中使用了一些面向对象编程的思想,是一种对于单片机/裸机硬件通信接口编程的共同性质的解决方案,能够解决一类抽象问题,那么这是一种设计模式么?毫无疑问这是一种模式,但并非一种设计模式,原因是这种做法能够良好的解决一类抽象问题,但是其应用范围仍然严重依赖底层实现而不能完全存在于逻辑抽象层面,因此这是一种模式或者说范式,但是并不能称为一种编程过程之中的设计模式。
现在让我们来考虑这样一种情形:我们需要一个类来表示某种信息完成某种任务,这个类在全局之中随时被各部分代码使用,并且我们希望这些代码使用的对象是同一个实例,并且这个实例的生命周期应当与整个应用程序运行的生命周期相同——当然这可以通过零散的全局变量和全局静态函数实现——但是讨论屎山代码并不是本小节的目的,那么我么也许可以这样写:
class GlobalManager{
public:
struct Deconstruct{
void operator()(GlobalManager* ptr){delete ptr;}
};
private:
static std::shared_ptr<GlobalSettings> instance;
static std::once_flag created;
//other member variables
public:
static std::shared_ptr<GlobalManager> getInstance(const Context* context = nullptr){
std::call_once(created,[context]{
instance.reset(new GlobalManager(context), GlobalManager::Deconstruct());
});
return instance;
}
GlobalManager(const GlobalManager&) = delete;
GlobalManager& operator=(const GlobalSettings&) = delete;
private:
GlobalManager(const Context* context = nullptr){
//constructor contnet
}
~GlobalManager(){
//destructor content
};
//other member functions
};通过如上的形式,在全局代码的任何一处使用GlobalManager::getInstance() 就能够得到唯一实例的共享指针,并且可以在初始化实例时传入一个上下文参数context 实现更加多样化的处理方法。对于任何的类来说,如果需要实现上文提出的需求,无论这个类的使用场景和业务逻辑都可以这样做,也就是将数据组织的形态和架构完全从底层实现之中脱离出来而升华到抽象层面,那么这就可以说是一种设计模式。事实上上文之中的代码以极其简陋的方式实现了单例模式希望的某些功能,然而因为此处作为例子出现,某些编码规范并为遵守,无伤大雅。
2. 为什么需要设计模式——如何避免屎山代码的诞生
笔者在中学时期接触到理工三大学科物理化学生物的时候就一直被一件事情困扰:看起来最复杂最不可琢磨的生物学除去那些经验理论本质上还是化学键以及化学反应,而化学反应从微观的角度看就是元素原子的物理特性的宏观表征,那么我们为什么还要设立这些学科?后来笔者发现在20世纪这些学科早期发展时曾经诞生了“交叉课程”例如《化学物理》,随后了解到一个观点“Different is More”。当问题的复杂程度急剧上升从量变阶段变成了质变时,事情的本质就会发生某种改变这就要求我们使用不同的思路和手段处理问题。人类解决复杂问题的方式自古以来都十分简单:分而治之,也就是将一个复杂的问题分解为一些不那么复杂的问题,最终化简为直觉操作、熟练操作、原子问题。那么在分而治之的过程之中,“治”就不是一个核心问题——只要正确的、足够次数的”分“就一定能够”治“,反而问题的核心变成了如何”分“。在分解问题的时候我们有两种不同的总的处理逻辑:
横向处理逻辑,或者说”组合“的逻辑是:将问题按照不同的阶段、步骤、变例拆解为复杂度下降的问题,而后通过不同的判断条件将其一一解决或者再次分割,最终达成目的。但是我们要了解到一点:问题的复杂性不会凭空产生也不会凭空消失,如果我们观察到解决问题的复杂性降低那么一定是复杂性产生了转移——在这种方法之中复杂性转换到条件判断之中去,最终非常可能产生冗长繁复的判断逻辑。
纵向处理逻辑,或者说”抽象“的逻辑是:不要关注于问题的复杂性本身,要关注问题产生和处理的“范式”,借用马克思主义哲学的话语来说就是不要过多关注矛盾方面的对立性,而是关注矛盾方面的同一性。总的来说,我们将问题的同一性范式进行总结,使用这个范式处理所有类似的问题,问题的不同方面和不同的处理逻辑归结为范式的变例而非范式本身的不同——复杂性转换为抽象范式的总结过程。
按照如上的总结,似乎两种处理方法各有优劣——在实际应用状况中确实——但是在软件工程尤其是现代软件工程之中后者是优于前者的,设计模式这一领域总的思想就是抽象的思想。在话语上枯燥的争论毫无意义,工程学总要依托于实际问题否则就会变成机械的或者形而上的无意义诡辩,让我们来看这样的一个例子:
假设你是一位游戏公司的软件工程师,你目前接到的业务需求是完成“防御塔”这一元素的攻击部分的代码,在你的游戏之中,防御塔有这样几种不同的阶段:
未显示:玩家的视野之中没有防御塔,因此基于游戏性能考虑,我们不应当渲染这座防御塔并且这座防御塔不应当有任何行为
未激活:玩家的事业之中出现防御塔,需要渲染该目标,但是玩家并未进入防御塔的攻击范围,此时防御塔不需要攻击
就绪:玩家处于防御塔的攻击范围之中,防御塔此时不处于冷却状态,应当立即发出攻击
冷却:攻击完成后防御塔需要进入冷却状态——如果攻击没有CD那么玩家一定会被程序脚本活活打死,这完全没有任何可玩性
已损坏:玩家向防御塔施加了足够的攻击并且造成了有效伤害,当防御塔HP归零时防御塔损坏,此时防御塔不应当有任何行为并且渲染为损坏的模型
然而形态和攻击方式单一的防御塔如果想要游戏具有难度和可玩性基本需要依赖地图编辑或者其他机制,你的同事们显然不愿意承担额外的工作任务,于是他们要求你完成不同种类的防御塔,每种不同的种类都具有不同的攻击、防御、CD、HP数值以及不同的外观模型需要渲染,大致有:
近防塔:CD中等,攻击力度稍弱,HP较高,防御力较低,单体攻击
远程塔:CD极长,攻击力度极大,HP较低,防御力中等,单体攻击
阵地塔:CD极短,攻击力度中等,HP中等,防御力较高,范围攻击
如果我们按照组合逻辑我们可以这样完成这一任务:
typedef struct {
int hp;
int cdInterval;
int cdLeft;
double posX, posY;
double sight;
int attack;
int defense;
Model normal;
Model destoryed;
} Tower;
extern vector<Tower> towers;
//Game main loop
void tick(){
//other codes
for(size_t i=0;i<towers.size();i++){
double distance = sqrt(pow(player.posX-towers[i].posX,2)+pow(player.posY-towers[i].posY,2));
if(distance>player.sight) continue;
if(towers[i].hp<=0)
towers[i].destoryed.render();
else {
towers[i].normal.render();
if(distance>towers[i].sight) continue;
else if(towers[i].cdLeft!=0) towers[i].cdLeft--;
else {
towerAttack(towers[i]);
towers[i].cdLeft=cdInterval;
}
}
}
//other codes
}这样看起来代码的实现似乎并不复杂,然而假设根据游戏封测结果,我们需要做出如下的调整:
防御塔的模型种类从两类变成:正常状态,损毁状态,受攻击状态,冷却中状态,攻击玩家状态
游戏地图设计变复杂,从二维地图变成三维地图,并且添加更多的真实物理效果,远程攻击路径上如果有障碍物则无法攻击
加入联机功能,游戏内可能出现多个玩家
我们会发现两个很尴尬的问题:
随着业务需求的不断变化,组合逻辑将会不断嵌套、条件将会不断变多,最终使得代码的可读性无限降低,这将会无限增高偶然犯错引起的大面积恶性BUG并且使新业务逻辑上线的速度大大降低,引起策划部门和开发部门之间的结构性矛盾。
函数
tick()由其他开发者书写并且很可能在其他的源文件之中,如果任何一个功能的改动都要联动其他源代码的改动,那么负责测试和代码审核的同事可能血压爆表并且BUG的排查工作可能让整个开发团队瞬间暴毙。
但是假设我们弃用这种组合分解的逻辑,使用抽象范式去归纳问题,那么我们可以将代码重构:
//将距离计算和判断使用单独的封装例如:
class Position{
public:
Position(double x,double y,double z);
void setPosition(double x,double y,double z);
static double distance(const Position& a,const Position& b);
//other codes
private:
double x,y,z;
//other codes
};
//将防御塔数据结构抽象为一个类
class Tower{
protected:
int hpLeft;
const int hpTotal;
int cdLeft;
const int cdInterval;
int attack;
int defense;
Position position;
const double sight;
Model normalModel;
Model destroyedModel;
Model attackingModel;
Model waitingModel;
Model attackedModel;
public:
//此处举例不编写构造器和析构器
virtual void attackPlayer(vector<Player*> targets);
virtual void attacked(vector<Player*> attackers);
virtual void rendModel(vector<Player*> observers);
void updateCooldown(int counting = -1);
};
//近防塔子类
class CloseInTower : public Tower {
//实现不同的虚方法,运行时绑定
}
//远程塔子类
class RemoteTower : public Tower {
//实现不同的虚方法,运行时绑定
}
//阵地塔子类
class CloseInTower : public Tower {
//实现不同的虚方法,运行时绑定
}
//在游戏进程之中调用这些实例:
vector<Tower*> towers;
vector<Player*> Players;
void tick(){
//other codes
for(size_t i=0;i<towers.size();i++){
towers[i]->rendModel(players);
towers[i]->updateCooldown();
towers[i]->attackPlayer(players);
towers[i]->attacked(players);
}
//other codes
}可以看到通过这样的抽象之后带来这样几个好处:
新的类型的防御塔只要集成父类
Tower实现对应的虚函数就可以通过面向对象的多态机制实现不同的攻击、受击、渲染等等判定。这样以来未来无论添加什么防御塔类型都仅仅需要写一个新的类通过测试之后集成到旧的代码之中,实现了业务逻辑的敏捷开发。对于所有防御塔共同的行为例如冷却时间倒计时
updateCooldown只要在父类之中直接实现方法就可以完成对应的行为,并且只要更改父类的行为就可以作用到所有子类之中,实现了代码的高复用率。主线任务
tick通过多态指针将所有的防御塔类型都抽象为父类指针处理,对应的方法在运行时通过虚函数表绑定对应子类函数,无论是修改父类还是修改子类都不用更改主线任务的代码,实现了代码的解耦。
因此整个设计模式领域所关心的任务,也是面向对象软件设计之中的工程规范都围绕着这样一个核心:通过抽象的方法避免冗杂繁复的组合逻辑不断累积,使得整个工程的代码实现高复用率,整体呈现出高内聚低耦合的状态。绝大多数的屎山代码产生的原因并不是使用了错误的算法而是在这个过程之中设计部门出现了失能,没有很好的完成抽象任务。
3. 设计模式引导我们如何思考——代码设计原则
了解错误的方法通常只是正确处理问题的第一步,设计模式的两个重点是可复用性和低耦合性,我们究竟应当如何应用范式去实现业务逻辑的有机化简和整合呢?首先我们应当了解在设计过程之中是什么阻止我们完成这样美好的目标:实际问题的多变性。
对于高可复用性的要求来说,我们讨论的主要是编译时(Compile Time)的可复用性,也就是不应当每次编译整个项目而应当仅仅关注于更改或者添加的业务逻辑部分,只有这样才能够降低测试和出现问题的可能性,避免重复工作。而一旦实际问题改变,我们的业务逻辑代码一定要产生对应的改变,那么改变的部分就会破坏掉可复用性,因此我们的整体思路是复用同一性的抽象部分,改变具象的实现。
而对于低耦合性来说,代码模块之间产生耦合的本质是业务逻辑关系的耦合性,这种耦合性会导致我们无法分离抽象和实现,本质上还是由于业务逻辑和实际问题随时间的变化导致此前已经完成的抽象切割不再成立。所以从另一个方面来看,我们在进行抽象工作总结范式的时候应当为未来可能出现的变化留出多态接口,使用面向对象的多态继承特性抵御变化。
在前文提到的《设计模式:可复用面向对象软件的基础》一书之中,GoF总结了这样8条设计原则应用在设计模式领域辅助我们的软件开发工作,这里需要着重指出的是,GoF23种设计模式是目前通行的范本,然而这些概念的提出至今已经有数个年代了——随着层出不穷的新设计新方法应用在软件开发领域,我们实际上需要整理出符合自己习惯和具体场景的设计模式而不能照搬他们——当教条主义盛行的时候,再好的金科玉律也会变成旧时代的桎梏。我们最终需要遵守的是”抵抗变化,提高抽象”这样的思想,那么相关的8条原则如下所示:
3.1 依赖倒置原则(DIP,Dependency Inversion Principle)
上层模块不应当依赖于底层模块,而应当依赖于抽象范式或者接口
抽象范式不应当依赖于具体实现,具体实现应当依赖于抽象范式
在我们的开发任务之中,上层模块通常来说较为稳定,而底层实现则随着环境的变化多变,因此问题分割为稳定的上层逻辑和多变的底层模块,然而上层代码无法抛弃底层代码运行,就像是我们要盖一座房子时不能够直接建造二楼而必须先搞定一楼和地基。这里举出这样一个例子:现代互联网基于OSI分层模型构建,无论是我们的嵌入式设备、PC、移动设备的通信都基于IP网络并且在其上使用TCP/UDP传输最终使用HTTP/MQTT/FTP等等多种多样的协议构造了繁盛的全球互联网。根据硬件网卡的不同,且不谈无线网络,仅仅着眼于有线网络也就是以太网问题就已经很复杂,硬件实现方式的不同、传输介质的不同都会影响底层编码。但是只要遵循IEEE802.3这样的标准,实现全双工MAC子层就可以在其上架构OSI分层模型。这其中IP网络就是上层模块,以太网卡和通信线就是底层模块,IEEE802.3标准就是抽象范式。
同样的抽象范式是连接底层模块和上层模块的统一接口,如果这种抽象范式受到具体实现的影响总是变来变去那么前面谈到的模块之间的分层松散耦合就无法稳定复刻,因此在具体实现细节的层面一定是抽象范式指导具体实现而不是相反——总的来说这就形成了一个倒置的结构,高层的逻辑指导上层的依赖和底层的实现协作,因此称为依赖倒置原则。
这里举出这样一个例子:假设我们目前打造一款WEB APP的后端,当某些条件发生时需要通知用户,而通知用户的办法是多种多样的,可能通过E-Mail或者通过蜂窝网络发送SMS短信,又或者通过社交媒体的接口例如微信通知……
不遵循DIP原则的屎山代码:
class EmailSender{
public:
//other codes
bool sendEmail(const std::string& message);
private:
//other codes
std::string emailAddress;
std::string smtpServer;
std::string smtpUsername;
std::string smtpPassword;
};
class ShortMessageSender{
public:
//other codes
bool sendMessage(const std::string& message);
private:
//other codes
std::string telephone;
std::string apiServer;
std::string apiSecret;
};
class Notification {
private:
//other codes
EmailSender* emailSender;
ShortMessageSender* shortMessageSender;
public:
//other codes
bool notify(const std::string& message){
if(emailSender==nullptr&&shortMessageSender==nullptr) return false;
else if(emailSender!=nullptr&&emailSender->sendEmail(message)) return true;
else if(shortMessageSender!=nullptr&&shorMessageSender->sendMessage(message)) return true;
else return false;
}
}缺点十分明显,Notification 类直接依赖于不同的消息发送类无法轻松扩展其他的消息发送方式,并且任何一个类的改变都会引起整个代码的改变,既不能复用也不能解耦完全不符合设计目标,一个遵循DIP的改造为:
class MessageSender {
public:
//other codes
virtual bool authenticate() = 0;
virtual bool send(const std::string& message) = 0;
virtual ~MessageSender() = default; //C++语法原因必须添加,否则编译/运行报错
protected:
//other codes
std::string apiAddress;
std::string target;
std::string apiAccount;
std::string apiCredential;
}
class Notification {
private:
//other codes
std::vector<MessageSender*> senders;
public:
//other codes
bool notify(const std::string& message){
static MessageSender* sender = nullptr;
for(size_t i=0;i<senders.size();i++){
sender = senders[i];
if(sender==nullptr) continue;
else if(!sender.authenticate()) continue;
else if(sender.send(message)) return true;
}
return false;
}
}
class EmailSender : public MessageSender {
//implementation
}
class ShortMessageSender : public MessageSender {
//implementation
}
class WechatSender : public MessageSender {
//implementation
}
//other message sender implementation通过父类MessageSender 及其虚方法实现了一个抽象标准接口,后续添加的任何消息发送器无论是通过怎样的具体实现方法只要集成这个父类并且实现虚函数即可正常工作,而且Notificaiton类的上层代码并不会因为这些实现细节而改变,也不依赖这些实现细节工作,通过基类的指针即可实现运行时绑定从而运用多态特性工作。
3.2 开放封闭原则(OCP,Open-Closed Principle)
我们设计的抽象应当对于扩展功能的逻辑代码开发,易于扩展,并且增加新功能时不应该对已有的经过测试可复用的代码大规模修改。也就是整个设计应当预留出扩展功能使用的接口。
但是设计好的抽象应当对于修改封闭,也就是说稳定的代码不应当被频繁修改,避免引入问题或者破坏现有功能,需要改变功能时应当通过继承和接口等方式。
此处使用一个电商营销常见的例子,假设我们在营销时原本区分普通满减方案、有优惠券方案、传统节假日折扣方案。现在如果需要引入对于购物节的折扣方案,也就是说我们要扩展原有的功能。
不满足OCP的代码示例:
//满减折扣
std::vector<double[2]> fullPriceDiscount = {
{100,8},
{200,18},
{300,38},
{500,68}
};
double discountPrice(OrderContext context,double originPrice,std::vector<Cupon> cupons){
//阶梯满减
for(size_t i=0;i<fullPriceDiscount.size();i++)
if(originPrice>=fullPriceDiscount[i][0])
if(i==fullPriceDiscount.size()-1||originPrice<fullPriceDiscount[i+1]){
originPrice -= fullPriceDiscount[i][1];
break;
}
//优惠券
for(size_t i=0;i<cupons.size();i++)
if(cupons[i].available(context,originPrice)){
originPrice -= cupons[i].discount;
Cupons::addCupon(context,cupons[i]);
}
//传统节假日
if(Calender::isHoliday(context.date)) {
//降价策略
}
//此处新增代码
if(Calender::isFestival(context.date)) {
//新降价策略
}
}
class Calender {
public:
//other codes
static bool isHoliday(Date date);
//新增判断购物节
static bool isFestival(Date date);
}可以看到如果需要完成新增功能就必须更改discountPrice 函数功能与Calender 类之中新增判断购物节的静态函数,这就使得新增功能需要更改原有实现好的测试通过的代码,容易引入新的问题,那么符合OCP的方案为:
class Order {
public:
//other codes
double countTotalPrice();
private:
Customer customer;
std::vector<OrderItem> items;
Date date;
std::vector<DiscountStrategy*> discounts;
};
class DiscountStrategy {
public:
virtual double getDiscount(Order* order) const = 0;
virtual ~DiscountStrategy() = default;
};
//价格计算函数实现
double Order::countTotalPrice(){
double price = 0;
for(size_t i=0;i<this->items.size();i++)
price += this->items[i].price * this->items[i].count;
//此处折扣策略代码无需更改
for(size_t i=0;i<this->discounts.size();i++)
price -= this->discounts[i]->getDiscount(this);
return price;
}
class NoDiscount : public DiscountStrategy {
public:
double getDiscount(Order* order) { return 0; }
}
class FullPriceDiscount : public DiscountStrategy {
//满减折扣策略
}
class CuponPriceDiscount : public DiscountStrategy {
//优惠券折扣策略
}
class HolidayPriceDiscount : public DiscountStrategy {
//节假日折扣策略
}
//仅需要此处新增代码
class FestivalDiscount : public DiscountStrategy {
//购物节满减策略
}通过统一的策略抽象类DiscountStrategy规范计算折扣的接口,其他的策略仅需继承父类并且实现对应虚函数即可独立的完成对于折扣策略的设置,并且添加任何的新增策略都无需更改已经写好的代码,实现了DiscountStrategy类对于扩展开放,而更新扩展策略无需改变原有代码,这样一来解耦的同时完成了原有代码本身的封闭性。
3.3 单一职责原则(SRP,Single Responsibility Principle)
在软件设计过程之中,降低耦合性的重要设计原则是:一个类的代码如果需要改变,那么应当只有一种业务逻辑的改变能够迫使这个类的代码进行改变,这个业务逻辑就称为这个类的职责
假设我们目前编写一个后端系统操作数据库的部分,这段代码主要包含对于其中“用户”的管理
数据库之中与用户相关的表假设有User和Group两个(考虑使用ORM)
一个User能够创建很多个Group,但是每个Group只能有一个leader,Group表中含有字段leader外键指向User的主键id
一个User能够加入很多个Group,一个Group也有很多个User,User表和Group表通过UserGroup中间表形成多对多关系,表中userId和groupId为联合主键,二者都是外键,对应User和Group的主键
在这个场景之中以下代码是违反SRP原则的:
class User{
//other codes
public:
static std::shared_ptr<User> createUser(Param params);
void delete();
bool isMatch(std::vector<Condition> conditions);
const std::vector<std::shared_ptr<Group>> getGroupsAsMember();
const std::vector<std::shared_ptr<Group>> getGroupsAsLeader();
}
void User::delete(){
//other codes
auto groups = this->getGroupAsLeader();
for(size_t i=0;i<groups.size();i++)
groups[i]->delete();
//other codes
}上述的代码之中User::delete() 函数实现了当一个Group之中Leader被注销,那么对应的Group就会解散的功能。但是我们说这样的代码是非常不良并且引起耦合问题的原因在于此时引发User代码改变的原因有两种:
User本身模型的改变或者业务逻辑的变更,例如User查找的匹配条件变更了策略,那么函数
User::isMatch很可能要修改Group本身的策略出现了改变,例如Leader注销后不是解散Group而是随机挑选剩下的成员其中一个作为Leader出现
可以看到假设第二种业务逻辑变更出现,完全不影响User模型的业务逻辑居然会引起User类的改变,这是违法低耦合性的设计目标的,这就给一个类引入了两个不同的职责,那么原有的逻辑可以这样更改:
void User::delete(){
//other codes
auto groups = this->getGroupAsLeader();
for(size_t i=0;i<groups.size();i++)
groups[i]->changeLeader(nullptr);
//other codes
}
class Group {
public:
//other codes
void delete();
void changeLeader(const User* leader){
//other codes
if(leader==nullptr) this->delete();
//other codes
}
}这样以来再次出现上文的第二种业务逻辑的变更状况时,无需更改User类,仅需要更改Group::changeLeader 函数之中对于变更后的Leader为空指针的判断情况即可完成对应业务逻辑的更改,这就实现了User作为一个类仅仅负责数据库中User模型更改的目标。
3.4 李氏替换原则(LSP,Liskov Subtitution Principle)
在书写抽象范式时,一个子类必须满足其父类的外特性,也就是所有父类对象正常生效的代码(无论是编译/运行时不出现错误还是业务逻辑上不出现问题)都要能够用任意一个子类对象替换,也就是继承关系必须满足(IS-A)的组合关系。
现在假设我们开发一个手机银行APP,我们需要计算该用户名下所有资产,该用户名下可能存在这样几种卡片/凭证:
借记卡:可以自由存入、取出资金,但是不允许超支
信用卡:可以自由存入、取出资金,允许透支信用超支取出资金
class BankAccount {
public:
//other codes
virtual double getBalance() = 0;
virtual bool withdraw(BankContext context, double amount) = 0;
virtual bool deposit(BankContext context, double amount) = 0;
};
class DebitCard : public BankAccount {
private:
double balance;
public:
//other codes
double getBalance() override {
return this->balance;
}
bool withdraw(BankContext context, double amount) override {
//other codes
if(balance >= amount) {
balance -= amount;
return true;
}else return false;
}
bool deposit(BankContext context, double amount) override {
//other codes
balance += amount;
return true;
}
};
class CreditCard : public BankAccount {
private:
double limit;
double debt;
double balance;
public:
//other codes
double getLimit() {
return this->limit;
}
double getDebt() {
return this->debt;
}
double getBalance() override {
return this->balance;
}
bool withdraw(BankContext context, double amount) override {
//other codes
if(balance + debt >= amount) {
balance -= amount;
if(balance < 0) {
debt += balance;
balance = 0;
}
return true;
}else return false;
}
bool deposit(BankContext context, double amount) override {
//other codes
if(debt > 0) {
if(amount >= debt) {
amount -= debt;
debt = 0;
balance += amount;
}else {
debt -= amount;
}
}
else balance += amount;
return true;
}
};
class Customer{
public:
//other codes
double getTotalProperty(){
double property = 0;
for(size_t i=0;i<accounts.size();i++){
if(typeid(*accounts[i])==typeid(DebitCard))
property += dynamic_cast<DebitCard*>(accounts[i])->getBalance();
else if(typeid(*accounts[i])==typeid(CreditCard))
property = property + dynamic_cast<CreditCart*>(accounts[i])->getBalance() - dynamic_cast<CreditCart*>(accounts[i])->getDebt();
}
return property;
}
private:
//other codes
std::vector<BankAccount*> accounts;
}观察上述代码,可以看到由于子类CreditCard 的函数getBalance 并未计入信用卡透支状况,因此在计算个人总资产的时候需要破坏掉多态继承的特性进行动态类型判断和组合逻辑处理才能够正确计算出个人总资产,这就严重违反了IS-A逻辑也就是LSP要求的同一性原则,对于这份代码应该更改为:
double CreditCard::getBalance(){
return this->balance - this->debt;
}
double Customer::getTotalProperty(){
double property = 0;
for(size_t i=0;i<accounts.size();i++)
property += accounts[i]->getBalance();
return property;
}这样一来就将两类银行账户的获取余额方法统一起来,当然其他部分的代码应当做响应的调整,但是这些调整对于说明LSP原则并无裨益因此在这里不再赘述。LSP原则是在设计过程之中运用面向对象多态特性并且保持代码简洁可读的重要原则。
3.5 接口隔离原则(ISP,Interface Segregation Principle)
对于一份代码或者一个抽象而言,其使用者不应当依赖/接收其使用不到的接口
对于一份代码或者一个抽象而言,其抽象接口应当是一个保持完备性的最小实现
假设我们目前正编写一个办公室文印设备管理系统,我们需要处理这样几种机器:
打印机,能够打印文件
扫描仪,能够将文件扫描为电子版本
传真机,能够扫描文件发出传真或者接收电子传真文件打印出来
复印机,能够扫描文件并且立即打印出来
一体机,能够完成上述所有任务
一个不符合ISP设计原则的糟糕的接口抽象代码如下所示:
class MultiFunctionDevice {
public:
virtual void print(const File& file) = 0;
virtual File scan() = 0;
virtual void transmitFax() = 0;
virtual void receiveFax() = 0;
virtual ~MultiFunctionDevice() = default;
}
class PrinterTypeA : public MultiFunctionDevice {
//内部实现
//不需要: scan() transmitFax() receiveFax()
}
class ScannerTypeB : public MultiFunctionDevice {
//内部实现
//不需要: print() transmitFax() receiveFax()
}
class FaxTypeC : public MultiFunctionDevice {
//内部实现
//不需要:print() scan()
}
class CopierTypeD : public MultiFunctionDevice {
//内部实现
//不需要:transmitFax() receiveFax()
}
class MultiTypeE : public MultiFunctionDevice {
//内部实现
}可以看到这个接口设计实现了完备性,但是完全没有能够实现最小封装,使用这个接口的具体设备或多或少都会存在不需要的接口,难道这些接口在运行时被意外调用需要抛出某种异常么?软件设计的金科玉律:用户不应当接收到错误!那么我们的接口应当这样进行改造以适配ISP原则获得更好的编码设计:
class Printer {
virtual void print(const File& file) = 0;
virtual ~Printer() = default;
}
class Scanner {
virtual File scan() = 0;
virtual ~Scanner() = default;
}
class Fax {
virtual void transmitFax() = 0;
virtual void receiveFax() = 0;
virtual ~Fax() = default;
}
class DeviceTypeA : public Printer {
//内部实现
}
class DeviceTypeB : public Scanner {
//内部实现
}
class DeviceTypeC : public Fax {
//内部实现
}
class DeviceTypeD : public Printer, public Scanner {
//内部实现
}
class DeviceTypeE : public Printer, public Scanner, public Fax{
//内部实现
}3.6 其他设计原则
以上五个设计原则是设计模式领域最重要的五大原则,也被称为SOLID原则(SRP,OCP,LSP,ISP,DIP)是软件设计过程之中时时刻刻要参考、遵守的编码规范,这对于提高可复用性和降低模块间耦合性非常重要。然而在书中GoF还提出了剩余三个较为常用的设计准则:
设计时应当优先使用不同对象的组合而非直接使用类继承创建新的抽象,这是因为类继承是一种“透明机制”而对象组合是一种“黑相机制”。使用类继承在某种程度上破坏了代码封装的隔离特征,子类代码和父类代码之间具有编译和运行上的耦合特征。反之,对象组合只要求被组合的对象具有良好的逻辑抽象接口而并没有编码语言语法上的硬性规范从而保证了较低的耦合性。
在创建抽象接口和划分具体实现时应当选择这样一种封装隔离点:让设计者和开发者能够在一侧进行符合业务逻辑的修改而不会对另一侧产生不良影响,使得整个代码框架根据抽象逻辑进行分层,例如著名的MVC模型,实现松散耦合。
开发者编程时应当能够针对接口编程而实现功能,而非根据功能反向设计抽象接口,这条准则事实上应当归类为技巧。例如我们不应当将变量声明为某个具体的特定的类而是某个接口,上层程序不应当关心下层代码返回的具体类型而仅仅应当关注下层代码的操作API……
无论是GoF23种经典设计模式,还是我们自己自主创造的某种模式,甚至说不一定局限于面向对象编程技术,在现代软件工程设计之中,保持代码的高复用性、松散耦合性、良好分层特征、整洁的代码格式是一种通行的优良习惯。而设计模式所着眼的问题正式如何将这些准则和习惯从思考方式和指导思想的层面转换为方法论的过程。