——从设计模式提高开发水平02
在GoF23类设计模式之中,出了用于使用多态特征创建对象的五种设计模式之外,另有7个设计模式用于调整对象的数据结构和组织形式以获得更加复杂或者便利于当前使用状况的对象,这些设计模式并不着眼于对象的创建或者具体的使用阶段,他们的核心在于处理对象和对象以及抽象和具体实现之间的组合关系和结构,因此被称为结构型模式(Structral Pattern)。随着我们业务逻辑的扩张和处理情况的不断复杂化,随之而来的就是抽象结构复杂化和冗余臃肿的问题,这个时候因此引发的各种不兼容或者高耦合性就要使用这些设计模式妥善处理。
0.结构类设计模式综述
众所周知,在面向对象编程的开发思路之中,整个开发过程就是抽象-实现-再抽象-优化实现的过程,而类作为抽象的代码载体是面向对象编程的核心特性,在上世纪80年代开始的一小段时间内,开发者们曾经提出了一个激动人心但是后来被证明不切实际的想法:一切皆对象。在这种初见光明辉煌的思路之下,开发者们抱着极大的热情投入了面向对象开发的转换热潮,但是其中有一部分缺点马上凸显出来:
性能问题:每一个类对象都要绑定虚函数表,都有自己独有的字段,多态特征需要依赖延迟绑定和间接寻址生效,这就导致了在某些应用场景之下普通的面向对象编程会引发存储空间、时间复杂度或者其他性能问题。例如:当一个类对象绑定的字段占用的内存空间较少但是这样的对象要创建成千上万个并且不断在进行创建和销毁动作的情况下,碎片化的数据管理和访问会引发性能问题。
兼容性问题:当我们将一种数据组织形式变为抽象之后,我们会处理各种兼容性问题:例如某种数据类型最好引出操作接口A,但是数据本身的特性最好抽象为操作接口B;又或者我们需要进行代码的升级换代,但是开发者并不处于绝对的真空之中,我们总要依赖支持库和其他人编写的可用代码,如果这时候某一个支持库不支持升级后的新特性应当怎么办呢;再或者我们完成了一系列的抽象和实现工作,但是这些接口同时暴露给客户端代码的时候过于繁冗的接口反而令上游开发者不知所措……
继承膨胀问题:在面向对象编程的开发方法之中,当我们建立了一个抽象之后在使用阶段或者重构阶段面对改变时,我们本能性地首先会想到使用继承的方法进行扩展而后就能够轻松的复用多态特征完成任务,但是这样就引发了继承膨胀问题,这个问题从两方面来看:首先是滥用继承会导致一个类完成的实现层面的代码过多导致一个新的屎山出现在抽象内部而后尾大不掉;其次是当一个抽象需要应付的实现层面的变数过多或者相互组合不可计数,那么我们需要实现的子类数量就会变得非常折磨。
因此本文介绍的七种结构型的设计模式并不像是之前讲到的创建型设计模式一样着眼于对象的构建或者是之后讲到的行为型设计模式一样注重于具体功能实现的技巧,这些设计模式核心的任务是处理已有的抽象的功能扩展、和其他抽象的相互配合、面向某种具体实现的抽象接口等工作,也就是用于调整抽象概念的结构(Structure)。概括的来说是以下三点:
组织类和对象的关系,使多个抽象能够保持可扩展性和低耦合性的基础上协同工作或者使单个抽象能够适配使用场景
优化类和对象的使用,针对多个抽象和联合使用或者一个抽象的分割使用设计不同的使用接口以节省资源占用提高性能
减少系统整体复杂性,考虑到抽象类继承膨胀的问题,在功能扩展时不过多的增加系统的维护难度、代码的可读性
结构型设计模式主要涉及如何组合类和对象以获得更大的或者更易用的结构,在这些模式之中我们需要转变思路,灵活的使用继承或者组合或者二者结合的方式去配置接口实现业务逻辑,进而能够变调整局部实现为调整抽象结构最终解决一大类问题,才能够称为结构型设计模式。结构型设计模式主要的共性和适用场景大致分为四类:
降低不同模块之间的耦合:在需要不同抽象模块协同工作的逻辑之中,通过调整抽象结构可以使得多个抽象结构分离使用,这样能够完成降低模块耦合度提升应用代码灵活性的目的,这里主要针对模块之间的耦合而非模块内部的耦合。
封装复杂的层次结构:当系统由多个子系统或者多个分层系统构成,而这些子系统的抽象可以在某个场景之中按照既定的规则使用时,提供统一接口可以显著降低客户端代码和开发者的学习和使用成本以及复杂度,同时提供更佳良好的逻辑管理。
提高可扩展性:当抽象的某一方面功能或者某一类变化具有不断扩展并且这些扩展会相互组合的特征的时候,一般来说不通过粗暴的继承或者组合或者局部的调整某个方法的实现去完成目标,而是要通过调整抽象本身的结构去适配这样的场景和需求。
优化资源利用和代码使用方式:当某个对象和其所代表的抽象碰到性能瓶颈并且瓶颈的产生不在于某一个方法之中具体算法的复杂度时,需要通过调节抽象结构的手段去优化资源利用,提高代码运行性能或者调优代码调用接口。
1.适配器(Adapter)模式
所谓适配器在我们日常生活之中见到的最多的就是电源适配器,本质上就是将市电或者工业用电转换为具体电器允许的标准的供电范围的电力电子器件,这里的核心在于“不同标准的转换”。在我们的开发过程之中经常能够碰到这种状况:我们使用两个不同的支持库,其中库A在逻辑上依赖库B进行工作,但是B的接口例如方法名称和参数以及返回值和A的需求不同——这时候难道要放弃使用这两个支持库么?这个时候我们想到的第一方案是设定几个“中转方法”获取A给定的参数之后计算出对应的B的参数并且调用方法,将返回值处理后返还给A,这样就是弥合转换了不同的标准。因此我们可以说这几种状况是合适的:
我们已经有一个构建好的抽象,我们想要不更改并且使用它但是它的暴露接口与我们期望的不相符
我们想要创建一个可复用的抽象,这个抽象应当与其他不相关的抽象或者不可预见的未来添加的抽象联合工作
我们有一些已经子类化的抽象,然而我们不能逐一对其构建中继接口,我们需要对其父类进行这一工作
对于第一种状况,我们举出这样一个例子:我们目前有一架等待程序控制的车辆,这个车辆是传统的转向架+后驱结构并且已经构建好了驱动程序,对于一个控制全向轮的上层代码如何使其联合工作呢?
首先我们假定既有的驾驶驱动程序抽象如此:
class Vehicle{
public:
enum Mode {
PARKING = 0x00,
FORWARD,
BACKWARD,
LOCKDOWN
}; //代表前进/后退/停泊/锁定的枚举
Vehicle();
void switchMode(Vehicle::Mode mode);
Vehicle::Mode getMode();
void speedUp(double delta);
void speedDown(double delta);
double getSpeed();
void turnLeft(double angle);
void turnRight(double angle);
double getDriection();
private:
double direction; //代表当前转向架的角度,正前方是0度,左侧为负右侧为正
double speed;
Vehicle::Mode mode;
};再假设我们希望的驱动接口为:
void setDirection(double angle); //以正前方为0度,逆时针为正设定前进方向
double getDirection();
void setSpeed(double speed); //沿着既定方向移动的速度
double getSpeed();
void setLock(bool enable); //锁定/解锁车辆那么我们可以通过一个很简单的组合逻辑构建这个新的抽象驱动类:
class VehicleAdapter{
private:
Vehicle* driver;
public:
VehicleAdapter(Vehicle* driver):driver(driver){};
void setDirection(double angle){
if(angle<=90&&angle>=0)
driver->turnLeft(angle);
else if(angle>=-90&&angle<0)
driver->turnRight(-1*angle);
else if(angle<=180&&angle>90){
driver->switchMode(Vehicle::BACKWARD);
driver->turnLeft(angle-90);
}
else if(angle>=-180&&angle<-90){
driver->switchMode(Vehicle::BACKWARD);
driver->turnRight(-1*(angle+90));
}
}
double getDirection(){
bool back = driver->getMode() == Vehicle::BACKWARD;
double direction = driver->getDreiction();
if(!back) return direction;
else {
if(direction>=0) return direction+90;
else return direction-90;
}
}
void setSpeed(double speed){
double origin = driver->getSpeed();
if(speed>origin) driver->seepdUp(speed-origin);
else driver->speedDown(origin-speed);
}
double getSpeed(){
return driver->getSpeed();
}
void setLock(bool enable){
driver->switchMode(enable?Vehicle::LOCKDOWN:Vehicle::PARKING);
}
};对于第二种情况我们举出这样一个例子:我们目前为系统的其他部分设定了两种记录日志的方案,也就是通过控制台打印日志信息或者通过文件系统写入日志信息到固定文件,但是未来很可能要使用其他的日志登记,例如发送日志到云端平台。
假设目前的两个日志输出抽象为:
class ConsoleLogger {
public:
explicit ConsoleLogger(const Color& color = Color::Default);
void print(const std::string& message);
void setColor(const Color& color);
private:
Color color;
};
class FileLogger {
public:
explicit FileLogger(const char* filename = "log.txt");
void write(const std::string& message);
private:
File file;
};那么我们可以通过二次抽象出这两个类的共性作为抽象目标接口并且分别建立适配器的方法统一接口:
//target interface
class ILogger {
public:
virtual void log(const std::string& message)=0;
virtual ~ILogger() = default;
};
//adapter for console
class ConsoleLoggerAdapter : public ILogger {
private:
ConsoleLogger* logger;
public:
ConsoleLoggerAdapter(const ConsoleLogger* logger):logger(logger){};
void log(const std::string& message){
logger->print(message);
}
};
//adapter for file
class FileLoggerAdapter : public ILogger {
private:
FileLogger* logger;
FileLoggerAdapter(const FileLogger* logger):logger(logger){};
void log(const std::string& message){
logger->write(message);
}
}这样还可以随时添加新的云端日志登记抽象,并且按照ILogger 统一的使用它们:
//new logger just implement ILogger
class CloudLogger : public ILogger{
private:
std::string serverAddress;
std::string secretToken;
public:
CloudLogger(const std::string& addr, const std::string& token);
void log(const std::string& message);
};
//construct logger(or adapater)
ILogger* fileLogger = new FileLoggerAdapter(new FileLogger("log-1.txt"));
ILogger* consoleLogger = new ConsoleLoggerAdapter(new ConsoleLogger(Color::Red));
ILogger* cloudLogger = new CloudLogger("log.my.domain:8888/api/log","******");
//use ILogger
ILogger* logger = cloudLogger; //select cloud logger
logger->log("New log message");第三种情况实际上就是第二种情况的一种简化,如果我们考虑一开始就已经给定了一个父类Logger 并且其他的对控制台,文件,云平台的日志抽象都是继承该父类完成的,那么我们构建适配器的时候可以直接面向Logger构建。前文举出的例子全部使用了组合逻辑嵌入了需要适配的抽象接口,实际上在具体的业务逻辑之中我们称被适配者为Adaptee 而称适配后的接口为Target ,只要不离开这些基本概念,无论何种实现方式都属于适配器的范畴。不过经验来说可以分为两类适配器的书写方法:
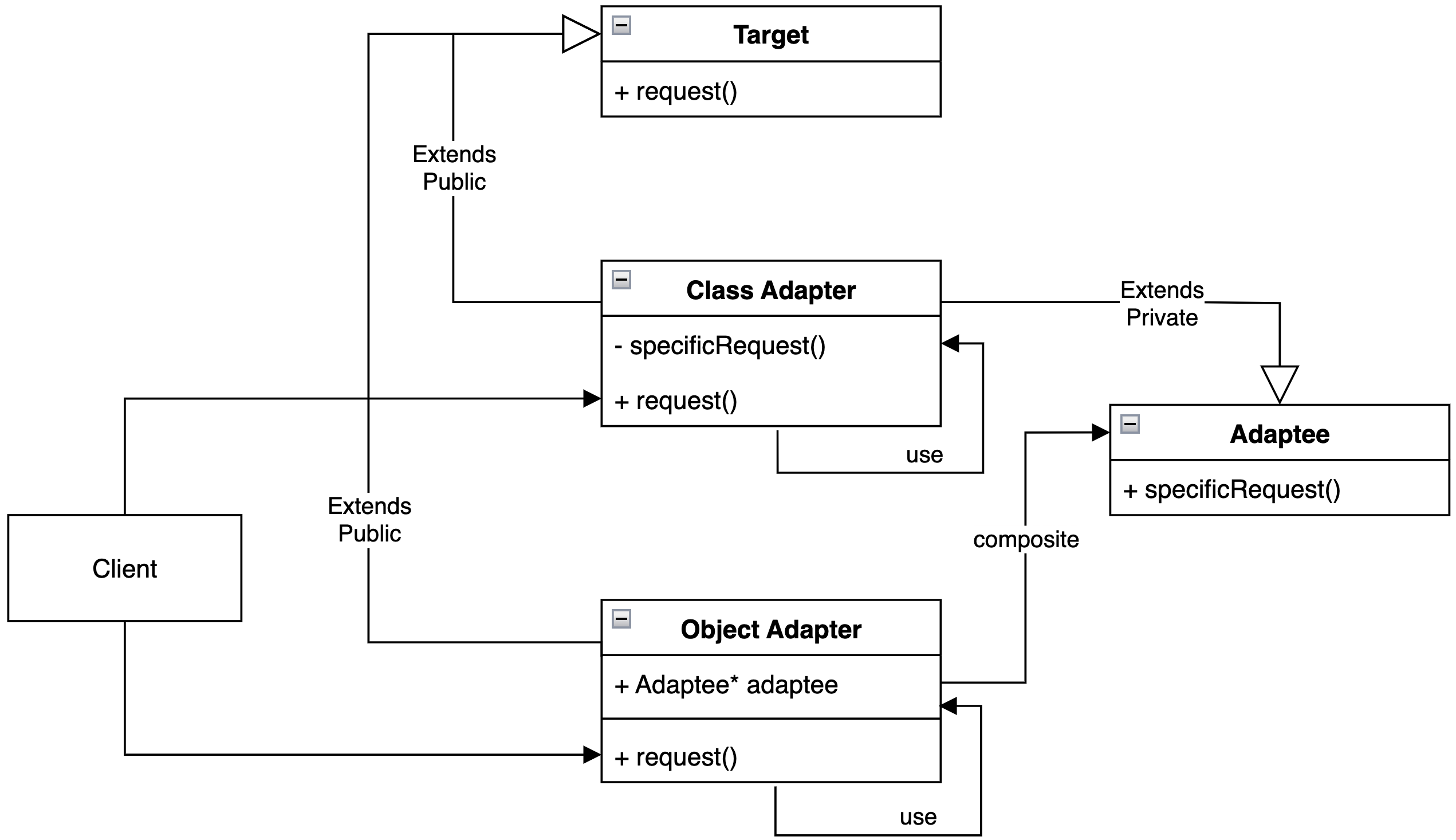
首先是类适配器或者说子类适配器,通过使用多重继承,能够让适配器抽象对象既能够拥有Target期望的特征又能够通过继承关系调用被适配的Adaptee的待适配方法,并且可以通过继承权限关键字避免用户误触Adaptee 的代码,一般来说这样书写:
class Target {
public:
virtual void request() = 0;
virtual ~Target() = default;
};
class Adaptee {
void specificRequest();
};
class Adapter : public Target, private Adaptee{
public:
void request() override {
specificRequest();
}
};我们可以这样总结这种适配器的适用场景以及优劣:
适用:适配器仅需适配单个
Adaptee并且需要访问其中的private或者protected成员或者方法,或者适配器扩展对应方法时无法脱离原本Adaptee的抽象结构上下文书写代码。优点:由于继承关系,不需要额外的对象或者成员,可以直接使用
Adaptee的上下文,并且可以扩展响应功能,通过private关键字设定继承关系权限,可以对客户端代码屏蔽接口防止误触。缺点:这种方法一定要使用多重继承,在其他面向对象语言之中例如Java只能将
Target变成接口然而C++确实可以将Target实现为普通基类而非纯虚基类,但是多重继承还是容易引起菱形继承或者其他的什么可维护性上的耦合之类的问题。
除了继承类的适配器之外,事实上目前最受欢迎使用的也更多更灵活的是对象适配器,也就是上文书写的例子。这种方式的特征是使用组合而非继承,也就是使Adaptee 的访问接口以成员的形式出现在Adapter 之中,而适配器仅实现接口Target 即可:
class Target {
public:
virtual void request() = 0;
virtual ~Target() = default;
};
class Adaptee {
void specificRequest();
};
class Adapter : public Target {
private:
Adaptee* adaptee;
public:
Adapter(const Adaptee* adaptee):adaptee(adaptee){}
void request() override {
adaptee->specificRequest();
}
};我们可以这样总结对象式或者组合式适配器的特性:
适用:适配多个不同的
Adaptee,只要Adapter拥有所有Adaptee对应的成员指针即可。尤其显著的适用场景为若干个属于一个父类的子类Adaptee不必要分别实现适配器,仅需要对父类进行适配即可。某些第三方不开放源代码的库也只能这样处理。优点:可以适配多个或者多层级的
Adaptee,使用最为灵活并且避免了多重继承的特点。因为Adaptee是通过组合耦合到代码之中的所以并不是编译阶段的耦合而逝运行时耦合,这就有了运行时动态调整的空间。缺点:需要额外的对象指针,并且因为运行时耦合绑定,所以可能带来轻微的性能开销。不同于继承式的适配器,由于和原有的抽象没有继承关系,所以没有办法直接访问私有或者保护的成员和方法,略微带来了一些开发和扩展功能方面的障碍。
近年来还有一种提法就是双向适配器(Bidirectional Adapter),也就是适配器的双方既是Adaptee 也是Target ,但是笔者认为这也是一个伪概念,因为这种结构其实就是按照需求配置两个适配器之后将实现存放到一个类抽象之中而已,不具有设计模式层面的本质性的概念区别或者结构性的改进。附上两种适配器的UML类图:
2.代理(Proxy)模式
适配器模式主要解决的是如何使一个已经构建好但是不符合我们设计接口的抽象能够通过我们设计的接口进行访问,如果使用对象式或者组合式适配器还能够完成多个适配对象或者多层次适配对象的接口访问工作。但是我们发现:适配器模式只能确定我们以何种方式/接口访问抽象而并不能改变访问抽象的过程或者说访问抽象的具体实现方式。
我们在开发之中经常性会碰到这样的问题:例如我们需要加载一张高分辨率的图片或者根据某个三维模型实时渲染的图像,又或者我们需要填写的字段需要通过网络或者数据库获取……这个时候如果同步阻塞等待资源加载完毕就会因为一个资源拖慢整个界面的加载进程,因此我们通常通过异步方式访问他们,而这时候就需要各种占位符以及对于加载过程的严格控制,因此就有了代理模式(Proxy Pattern),我们可以这样概括代理模式使用的时机:
访问的资源受限,即访问动作本身收到管制,形成独立过程,例如访问数据库或者服务器时,这种情况要处理访问过程之中的诸多环节例如权限审核或者拒绝访问的异常处理等情况
访问的资源开销极大,也就是访问动作本身会占用远高于其他资源正常访问动作的资源,这种情况一般出现在资源懒加载的应用场景,例如页面之中有一个渲染十分复杂的图像
访问本身是远程的,例如从网络获取资源或者通过RPC进行管理或者同步动作,也就是抽象和具体数据在逻辑意义上是分离的,这时候加载的过程也具有相当的独立性导致访问过程复杂,因此需要调整结构
对于上文第一种状况而言,我们可以这样更严谨的概括:当访问对象的过程本身需要进行附加内务处理(Housekeeping Task)即访问过程本身需要进行预处理或者后处理的情况下应当使用代理。这种代理被称为保护代理(Protection Proxy),例如:
假设目前使用C++运行的代码目的是构建一个后端服务器,这个服务器可以通过远程管理,那么问题就出现了:不能允许不经审核或者没有管理员管控权限的访问通过资源审查,我们假设
BackendServer这个类代表服务器本身,那么:
//统一接口
class IServer {
public:
virtual void access() = 0;
virtual ~IServer() = default;
};
//真实服务器抽象
class BackendServer : public IServer {
public:
void access() override {
//sth. implemented by real backend server
}
};
class ProxyServer : public IServer {
private:
std::string& credential;
BackendServer* server;
public:
ProxyServer(const BackendServer* server):server(server){}
void setCredential(std::string& credential){
this->credential = credential;
}
void access() override {
if(!Authentication(credential).pass())
throw std::runtime_error("Unauthorized Access");
else server->access();
}
};保护代理(Protection Proxy)的适用场景,优缺点如下:
适用:访问过程本身需要严格管控,例如需要授权或者凭据,又或者一个可共享的资源其总连接数量需要管控……总而言之当访问过程本身具有独立性而且预处理或者后处理的目的是为了在某些条件下关闭访问
优点:增强访问过程的安全性,防止未经授权的访问,通过在代理抽象之中预留适当的接口可以以较低的耦合度灵活控制访问权限
缺点:增加了系统的复杂度,提高了维护和运行时的开销,引入的权限控制管理逻辑容易引发尚未预料的故障或者逻辑错误
上文第二种状况其实是应用代理模式最常见的情况,这种状况被我们称为虚拟代理(Virtual Proxy),我们可以更加严谨的定义这种状况:访问过程本身并不重要,但是访问过程本身耗费巨大的开销,因此我们需要控制访问发生的具体时机,在访问发生之前需要某个抽象的实现作为占位出现。较为常见的状况是:
假设我们目前在渲染一个界面,界面本质上是一个文档,这个文档含有一些高清图像,这些图像加载需要消耗大量图形运算资源,故而优先使用占位符渲染文字和布局,随后当图片出现在用户视野内时才加载具体内容
class Image {
protected:
int width;
int height;
uint8_t** pixels[3];
public:
virtual void display() = 0;
virtual ~Image() = default;
};
class HighQualityImage : public Image{
private:
std::string filename;
public:
HighQualityImage(const std::string& filename){
//other codes
loadFromDisk();
//other codes
}
void display();
void loadFromDisk();
};
class ProxyImageHQ : public Image {
std::string filename;
std::unique_ptr<HighQualityImage> image;
public:
ProxyImageHQ(const std::string& filename):filename(filename),image(nullptr){}
void display() override {
if(!image) image = std::make_unique<HighQualityImage>(filename);
image->display();
}
};虚拟代理(Virtual Proxy)的适用场景和优缺点如下:
适用:当被访问的资源加载过程占用资源较大或者加载时间较长,并且需要通过其他抽象的实现进行占位时,通过懒加载技术也就是延迟加载过程的手段控制时,应当使用虚拟代理
优点:仅在需要时创建或者渲染真实对象,节省内存,启动时间或者其他什么运算资源,适用于大资源加载
缺点:增加了代码复杂度,需要维护懒加载的代理抽象逻辑,这个过程有时需要额外注意多线程安全问题
上文最后一种状况是“代理”这个词经常出现的场景——网络,或者说“远程”,也就是资源实际存储位置和抽象代码运行位置在地址空间上并不连续,即便我们申请的网络资源和申请的代码处于同一物理机甚至说同一个容器之中,只要调用代码无法使用内存寻址或者磁盘加载的方式获取到资源就可以算作远程。这时候基于加载过程的复杂性和加载时间的长度我们经常使用代理,这称为远程代理(Remote Proxy)。一些操作数据库的ORM其中也有远程代理设计模式的元素,例如在Node.js开发之中大名鼎鼎的Sequelize。总的来说只要碰到远程资源访问的情况,为了隐藏网络通信细节,降低客户端和服务端之间的耦合性,一般而言我们会使用远程代理模式,其代码组织与前两种大同小异,还是要回归到抽象出一个客户端和服务端统一的接口,编写一个子类实现这个接口并且管控连接的流程这个路子上面来。
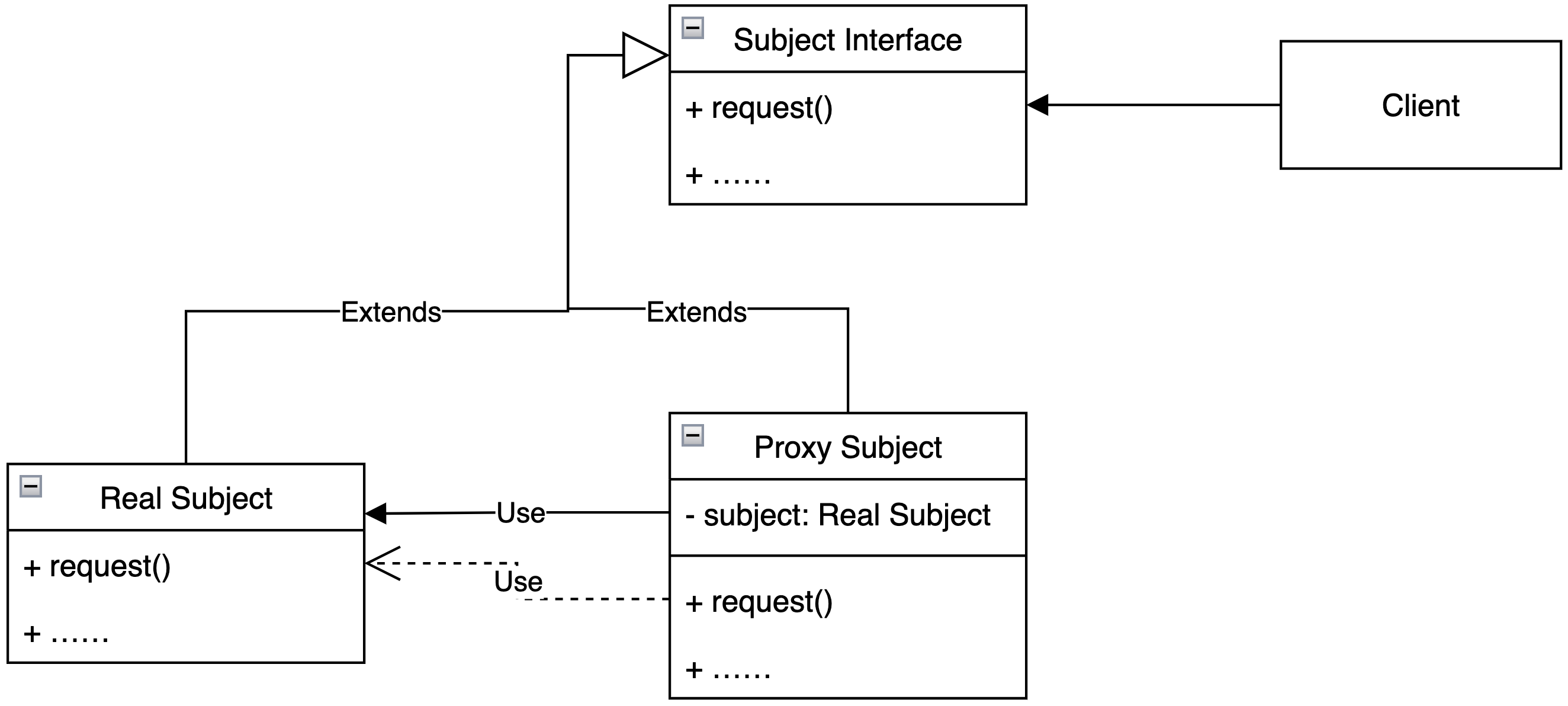
十分有趣的是代理模式最大的应用之一是在C++语言下管理指针和引用,大名鼎鼎的智能指针(Smart Reference)shared_ptr 本质上就可以看作一个线程安全的保护代理,当然在GoF的书中这种情况被单独拎出来讨论了,整体而言代理模式不仅仅可以应用在对象创建或者访问上,例如某个对象的深拷贝操作十分复杂,那么完全可以在复制引用时不进行拷贝,而在引用被交付访问时才进行真正的拷贝写入动作……整个代理模式的核心思想是:
提供一个代理对象等效真实对象,代理对象控制对于真实对象的任何访问
客户端代码禁止直接与真实对象进行交互,所有的操作通过代理对象达成
代理对象最小功能要实现对于真实对象的等效,但是可以添加额外的增强功能
下面简单实现一个shared_ptr 以展示代理对象在整体系统之中的作用,功能简易,仅作样例:
template <typename T>
class SmartPtr {
private:
T* ptr;
std::atomic<size_t>* refCnt;
public:
//Consturctor(default)
explicit SmartPtr(T* p = nullptr)
:ptr(0),refCnt(new std::atomic<size_t>(p?1:0)){}
//Copy Constructor
SmartPtr(const SmartPtr& other)
:ptr(other.ptr),refCnt(other.refCnt){
if(ptr) (*refCnt)++;
}
//Move Constructor
SmartPtr(SharedPtr&& other) noexcept
:ptr(other.ptr),refCnt(other.refCnt){
other.ptr = nullptr;
other.refCnt = nullptr;
}
//Copy
SmartPtr& operation=(const SmartPtr& other){
if(this==other) return *this;
release();
ptr = other.ptr;
refCnt = other.refCnt;
if(ptr) (*refCnt)++;
}
//Move Copy
SmartPtr& operation=(SmartPtr& other) noexcept {
if(this==other) return *this;
release();
ptr = other.ptr;
other.ptr = nullptr;
refCnt = other.refCnt;
other.refCnt = nullptr;
}
//Destructor
~SmartPtr() { release(); }
//Get real object pointer/reference count
T* get() const { return ptr; }
size_t useCount const { return ptr ? *refCnt : 0; }
//release
void release() {
if(ptr && refCnt){
if(--(*refCnt)==0){
delete ptr;
delete refCnt;
}
ptr = nullptr;
refCnt = nullptr;
}
}
//Reference redirect
T& operator*() const { return *ptr; }
T* operator->() const { return ptr; }
//nullptr
bool unique() const { return useCount() == 1; }
explicit operator bool() const { return ptr != nullptr; }
};最后附上代理模式的UML类图:
3.享元(Flyweight)模式
前文介绍的两种设计模式主要是为了针对已经存在的抽象调整接口的访问形式和访问过程,本质上是不改变抽象本身的结构而对抽象的外部特性或者说访问等效特征的相关结构进行调整。从现在开始我们对于抽象的结构层次的讨论需要逐渐深入,当我们讨论抽象的结构的时候必然涉及到多个抽象或者一个抽象的多个实现之间的关系——享元模式(Flyweight Pattern)就是对于细颗粒度抽象划分情况的一种处理办法。这里我们需要先明确颗粒度或者说粒度的概念。
颗粒度,近年来已经被标签化为“互联网大厂黑话”的一部分,但是我们返璞归真的来看,这个词汇实际上是用于表述业务逻辑划分的一个关键性的定义——假设对于一个整体性的业务逻辑要建立抽象,那么应当划分到什么程度?例如说我们需要完成一个文档编辑器,那么其中最小的对象抽象是什么?一段文字?一行文字?或者说一个文字?这三种不同的划分方式就是颗粒度不断细化的过程。那么这里提到一个题外话,为什么大家都说要“对齐颗粒度”?事实上不是说颗粒度越小或者越大就越好,颗粒度应当适配项目的目标而不损失过多的性能带来过多的开销,而最为关键的是各个部分之间的颗粒度不能存在太大的差异。例如如果做文本字体渲染的代码认为最小的渲染单位是一段话,那么对于将对象抽象细化到每个字符的另一份代码来说就会出现协同性问题。
那么为什么不尽量降低颗粒度呢?例如说每一个原子级别的数据都有一个对应的对象,这既符合“万物皆对象”又能够兼容任何高颗粒度的其他代码岂不美哉?我们来考虑这样一个问题,别的不谈,就说笔者目前书写的文字,至此已有字符13K+,如果每个字符甚至极端些每个像素点都对应一个对象,怕是不久就能闻到内存条的体香……这就是细粒度应用最大的缺点:大量的小对象产生大量的运行开销,占据巨量的内存导致整个项目走向不可避免的全盘失败。
这时候我们发现一丝熟悉的气息——多个极度相似的小型碎片化对象,我们需要一种“快速复制”的操作来换取高昂的复杂度,但是这就需要切割对象——如果要使用复制的方法那么就需要区分出“变动”和“不变”的部分,前者是不能够粗暴复制的。因此我们的思路可以更加明确的进行这样的概括:
需要创建大量相似但是不完全相同的对象,导致运算压力或者内存空间消耗过大
这些对象的部分状态是不随着上下文(Context)改变的,这部分内容可以通过快速复制的方法进行实现,也就是共享池(Share Pool)
基于第二点考虑调整对象的结构为可共享的内部状态(Intrinsic State),以及根据上下文随时改变的外部状态(Extrinsic State)
共享的对象需要持久化存在并且不断被复制,因此需要留存类似于原型模式的“原型”
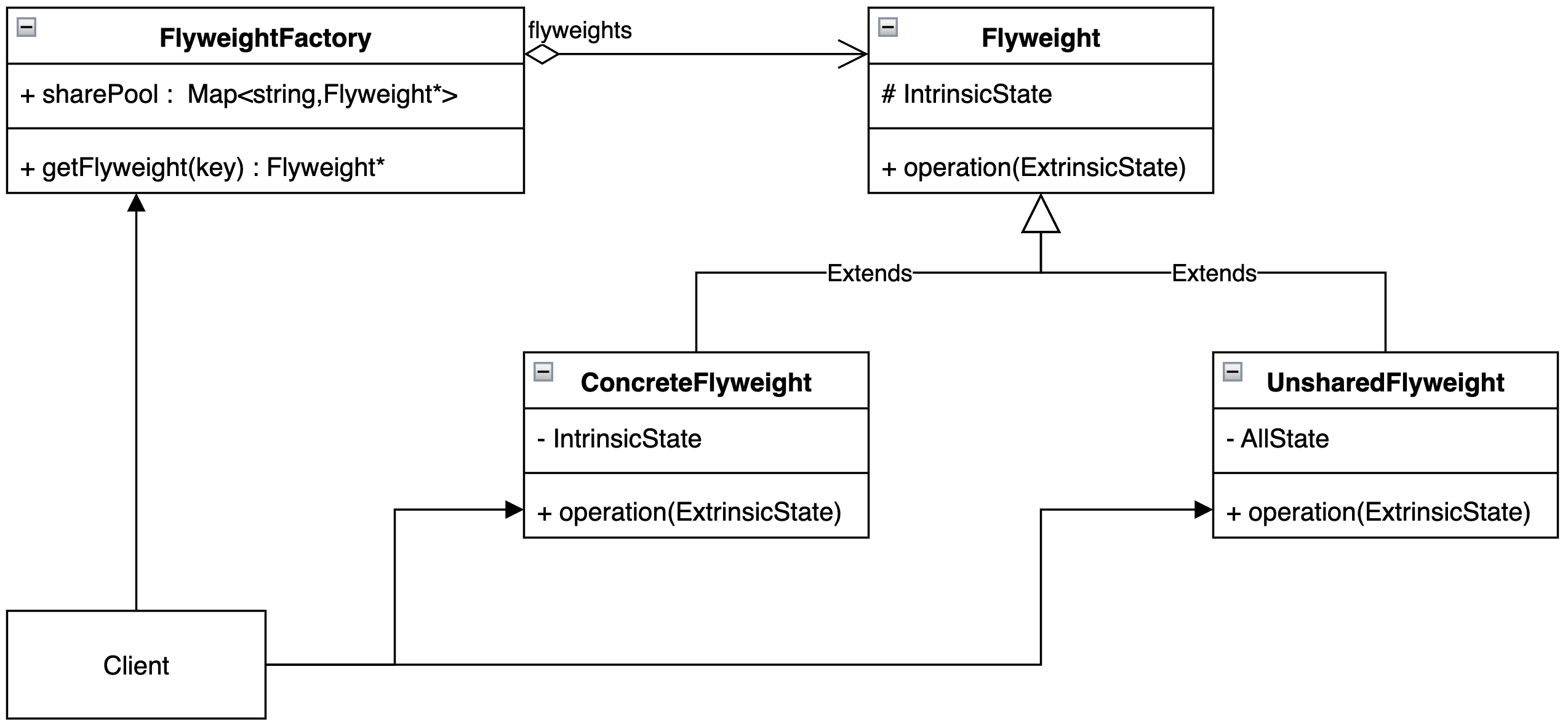
进而我们这样调整整个抽象的结构:
将可复制可共享的抽象称为具体享元对象(ConcreteFlyweight),并且从这些子类之中抽象出享元接口(Flyweight)
剩余的子类称为非共享享元对象(Unshared Concrete Flyweight),他们的特点是与其他子类相比特性多共性少,不参与共享复制
在享元接口(Flyweight)之中划分为内部(Intrinsic)状态存储在成员之中,外部(Extrinsic)状态通过方法参数或者上下文解析
获取所有“原型”享元的具有部分“创建”特性的结构称为享元工厂(Flyweight Factory)主要管理享元对象的共享缓存池
我们举出这样的一个例子:
假设我们目前负责某个场景渲染程序其中树木植被的渲染开发工作,目前进行到数据组织部分,一个场景之中的树木可能有成千上万,其中固然有十分漂亮的,就有特点的‘优良树种’,但是也存在大片只有位置和形态略有不同的普通树木,如果将它们每个都作为一个对象处理那么可能带来过多的内存开销,这时候需要使用享元模式。
//Flyweight
class TreeFlyweight {
protected:
Model model;
public:
virtual void display(int x,int y,double direction,const Context& context) = 0;
virtual ~TreeFlyweight() = default;
};
//Concrete Flyweight(Shared)
class Coniferous : public TreeFlyweight{
private:
std::vector<Color> leafColors;
Coniferous(const Model& model,std::vector<Color> leafColors);
public:
void display(int x,int y,double direction,const Context& context){
//implementation for coniferous tree
}
friend class TreeFlyweightFactory;
};
//Concrete Flyweight(Shared)
class BroadLeaved : public TreeFlyweight{
private:
Model leafModel;
BroadLeaved(const Model& treeModel, const Model& leafModel);
public:
void display(int x,int y,double direction,const Context& context){
//implementation for broad-leaved tree
}
friend class TreeFlyweightFactory;
};
//Unshared concrete flyweight
class UniqueTree : public TreeFlyweight {
private:
Annonation annonation;
public:
UniqueTree(const Model& treeModel, const Annonation& annonation);
void display(int x,int y,double direction,const Context& context){
//implementation for unique tree
}
void (*uniqueShow)(const Context& context);
};
//Flyweight factory
class TreeFlyweightFactory {
private:
std::unordered_map<std::string, std::shared_ptr<TreeFlyweight>> trees;
public:
template<typename... Args>
std::optional<std::shared_ptr<TreeFlyweight>> getTree(
const std::string& name, const Model& treeModel, Args&&... args){
if(trees.find(name) == trees.end()){
if constexpr (sizeof...(args) == 1){
if constexpr ((std::is_same_v<std:::decay_t<Args>, std::vector<Color>> || ...))
trees[name] = std::shared_ptr<TreeFlyweight>(
new Coniferous(treeModel, std::get<std::vector<Color>>(std::tuple<Args...>(std::forward<Args>(args)...)))
);
else if constexpr ((std::is_same_v<std::decay_t<Args>, Model || ....))
trees[name] = std::shared_ptr<TreeFlyweight>(
new BoradLeaved(treeModel, std::get<Model>(std::tuple<Args...>(std::forward<args>...)))
);
else return nullopt;
}else return nullopt;
}
return trees[name];
}
size_t getTotalCount() const { return trees.size(); }
};这段代码主要完成的工作:
制定了
TreeFlyweight享元接口,客户端代码调用该接口可以执行display方法将针叶林
Coniferous和阔叶林BroadLeaved两类具有可复制性的普通树种子类化:首先分离了内部状态也就是树的模型
TreeFlyweight.model,渲染使用的位置、方向、上下文通过display方法传入参数其次在子类化过程之中添加了各自这一类树木的属性例如叶子的颜色和叶子的模型,这部分也是内部状态,但是对于使用享元接口的客户端代码不可见,属于不可接触的内部属性
最后将各自的构造器全部声明为
private这样避免客户端代码误触调用,通过友元关系确定了树木一定通过工厂创建
对于特殊树种
UniqueTree虽然依旧继承了享元接口,但是由于其特殊性和少量性并为划归到共享池之中书写了管理缓存共享池的工厂类
TreeFactory并且通过方法getTree灵活的处理了不同的可变参数对应的不同树种大类的构造器
对照如上代码,我们可以这样总结享元模式的适用场景:
一个子系统或者整个APP之中使用了大量的对象
完全由于使用大量的相似对象,造成了很大的运算压力和存储开销
对象的大多数状态是根据场景和上下文变化的,能够转变为外部状态
如果删除掉对象的外部状态,那么可以用很少几个对象取代相比来说非常多的对象
应用程序的其他部分对于共享不敏感,也就是依赖于对象的值而非地址
使用享元模式得到的效果以及可以预期的提升或者问题有:
传输,查找共享对象,计算外部状态带来额外的时间开销,这里的策略是时间开销交换存储压力
因为共享对象的存在,减少了实例总体的数目从而能够降低整体的存储压力
对象可划分为内部状态的变量占据空间越大就会缓解越大的存储压力
对象必须划分为外部状态的变量以及这些变量的计算复杂度越高就会带来越高的交换时间复杂度
在上文渲染树木的代码之中,阅览过创建型设计模式的朋友应当感到十分熟悉——这和原型模式及其相似:通过一个工厂产生原型,工厂类附带管理原型,使用对象时都需要通过这个工厂类调用原型,都能够简化因为抽象设计本身特性衍生的问题……然而这两种设计模式仅仅是形似而神不似,其对于抽象的调整是有本质性区别的:
享元模式的生效区段是抽象本身的结构,偏重使用过程,而原型模式生效区段是对象创建过程
享元模式的根本性目的是减少重复对象的空间占用,用时间换空间,而原型模式根本性目的是避开复杂的创建过程,以空间换时间
享元模式管理“原型池”的目的是实现共享,让多个虚拟对象复用一个实例,而原型模式管理“注册表”的目的是为了创建新实例
享元模式必须要区分内部状态和外部状态,而原型模式则是拷贝原型实例的所有状态不做使用层面的区分
最后给出享元模式的UML类图:
4.门面(Facade)模式
如果说享元模式是典型的“分割”的艺术,那么本小节探讨的主要就是”总成“的思路。本文的主要着眼点就是探讨对于抽象结构变换的几种常见的设计模式,从本模式开始将脱离对于单一抽象或者一类抽象内部结构的讨论,开始关注抽象自身组合或者抽象之间组合形成更大抽象结构的问题,其中门面模式(Facade Pattern)也称作外观模式就是这种思路之中最浅显易懂的一个。插入题外话:Facade并不是一个英文单词,而是一个法文单词Façade,意为正面,前方。
我们考虑这样一个面对C/C++项目的自建CI/CD系统:
Git子系统:用于承接来自GitLab服务器的Commit/Merge信号触发的WebHook并且将代码拉取到本地
依赖子系统:用于下载编译需要的各类链接库和支持包以及
pkgconfig信息或者交叉编译平台编译子系统:用于通过
CMake编译源代码,处理编译报错或者编译产生的Target封装子系统:用于根据
Dockerfile拉取基础Docker镜像并且封装全新的可运行容器镜像并推送到仓库或者部署到生产/测试环境
其对应的各个子系统接口可能为:
class GitMonitor {
public:
enum Signal {
COMMIT = 0x00,
MERGE,
REBASE,
NEW_BRANCH,
DEL_BRANCH,
ARCHIVED,
DELETED
};
enum Authentication {
HTTP_PASSWD = 0x00,
HTTPS_PASSWD,
SSH_KEY,
GPG_KEY
};
void signalHoook(GitMonitor::Signal signal, const std::string& triggerSource);
bool fetch();
bool pull(const std::string& branch);
bool testConnection();
void setUsername(const std::string& username);
void setCredential(const std::string& crendential,GitMonitor::Authentication method);
GitMonitor(const std::string& projectLink);
~GitMonitor();
private:
std::string projectLink;
std::string username;
std::string credential;
GitMonitor::Authentication method;
};
class DependencyManager {
public:
size_t getDependencyCount();
std::string& getDependencyReport();
void loadDependencies();
void fetchDependencies();
void resolve();
DependencyManager(const std::string& configName, const std::string& sysrootName = "");
~DependencyManager();
private:
std::string cfgFilename;
std::string sysRootName;
std::vector<Dependency> satisfied;
std::vector<Dependency> outdated;
std::vector<Dependency> requring;
};
class CmakeCompiler{
public:
bool resolveCMakeList(const std::string& txtPath);
bool compile();
std::string getResult();
CmakeCompiler(const std::string& cmdPath);
~CmakeCompiler();
private:
std::string cmakeCommandPath;
std::string CMakeList
std::string compileResult;
}
class Deployer {
public:
Deployer(const std::string registry, const std::string crendential);
~Deployer();
bool fetchImage(const DockerImage& image, const std::string registry);
bool resolve(const std::string& dockerFilePath);
bool package(const std::String& targetImageName);
bool pushImage(const DockerImage& image, const std::string registry);
bool deploy(const std::string& dockerRuntime);
private:
std::string dockerRegistry;
std::string credential;
};这样的接口没有问题,职责划分清晰,没有冗余或者交叉功能,形成了子系统之间的低耦合高内聚特征。但是我们不免碰到一个问题:系统的低耦合度代表了对外的低集成度,这实际上给客户端代码增加了大量的工作,提高了使用的复杂性,显著的允许了客户端代码因为误触或者阅读文档不谨慎出现错误使用的概率。特别是整个CI/CD系统应当按照以下流程工作:
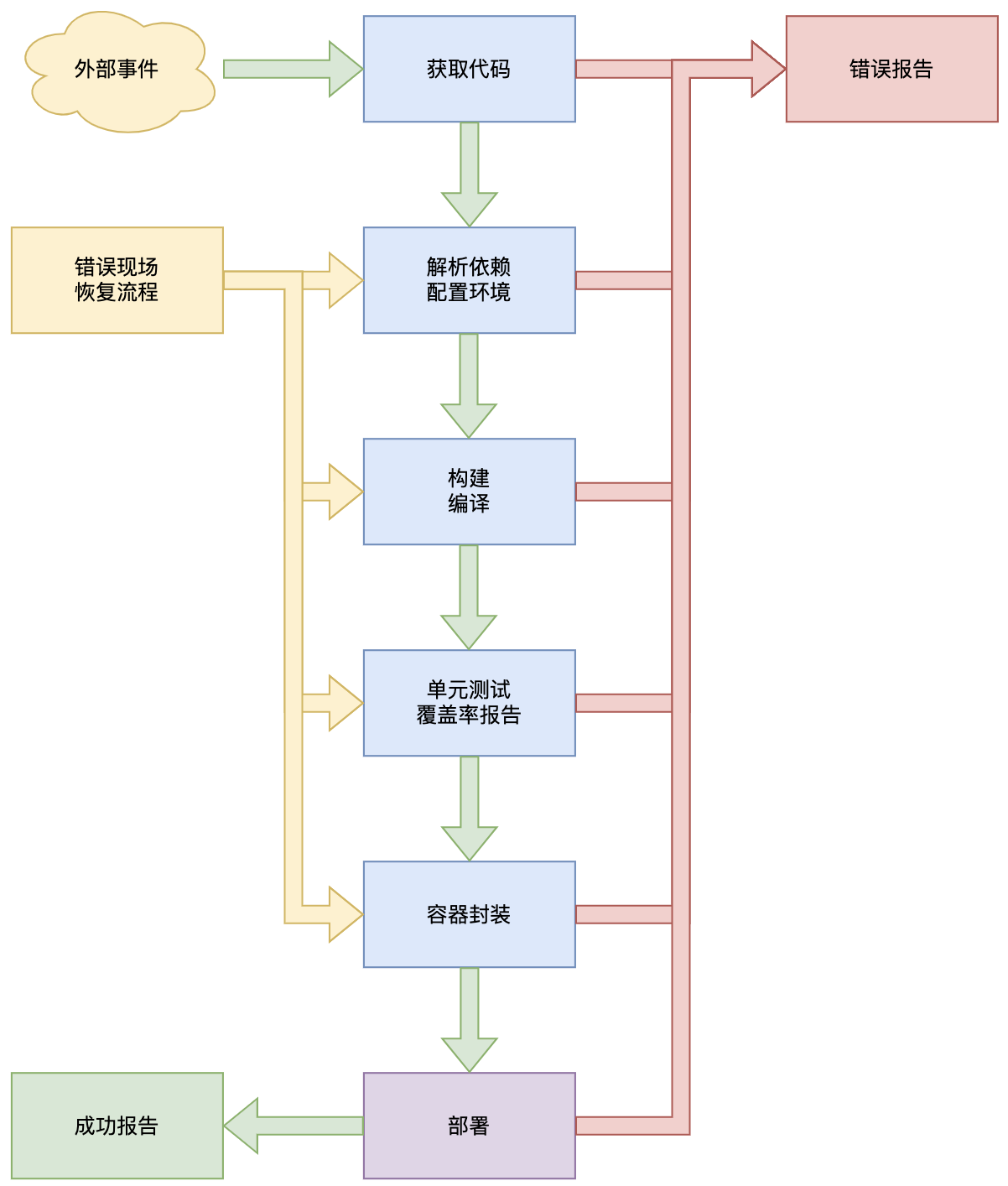
而且未来的子系统可能进一步扩展,例如:Git可能扩展为一个VersionContorlMonitor 接口,包含Git和SVN或者其他的什么版本管理工具,当然其他子系统也有这种改变……在这种情况下,让客户端代码控制整个流程是不恰当的,这会造成客户端代码直接和子系统进行耦合而不是具体的业务逻辑对应的抽象耦合,因此在这种流程既定的模式下,我们不妨使用这样一个类控制整个流程并且对客户端暴露:
class Pipeline {
public:
enum Stage{
Initial = 0,
Pull,
Prepare,
Build,
Test,
Package,
Deploy
Pass,
Fail
}
Pipeline::Stage status(){return this->stage;}
void init(){
//implementation
}
std::string run(){
std::string report = GetSystemTimestamp() + "Pipeline Started";
stage = Pipeline::Initial;
try{
init();
stage = Pipeline::Pull;
vc->pull();
stage = Pipeline::Prepare;
dm->resolve();
stage = Pipeline::Build;
tb->build();
stage = Pipeline::Test;
utm->unitTestAll();
utm->cover();
stage = Pipeline::Package;
cb->pull();
cb->resolve();
cb->build();
stage = Pipeline::Deploy;
dp->exec();
}catch(std::runtime_error e){
stage = Pipeline::Fail;
report += GetSystemTimestamp() + e.what();
return report;
}
stage = Pipeline::Pass;
report += GetSystemTimestamp() + "Pipline Pass";
return report;
}
private:
Pipeline::Stage stage;
VersionController* vc;
DependencyManager* dm;
TargetBuilder* tb;
UnitTestManager* utm;
ContianerBuilder* cb;
Deployer* dp;
};这就集成了多个子系统的功能并且控制了整个流水线,此后客户端书写代码的目标就不再是子系统本身,而是面向这个新的类Pipeline 书写代码执行整个CI/CD流程。这样将多个子系统合并为一个操作接口的方式叫做门面模式(Facade Pattern),这个作为操作接口的类称为外观类(Facade Class)。这里需要注意:由于门面模式之中子系统存在扩展性,需要使用多态特征故而多用组合的方式耦合到外观类之中,这使得外观类的构建难度和复杂度大大增加,这时候应当采用构建器或者原型又或者单例模式的方式消解这种复杂性,具有多个统一抽象接口子系统的门面类在实际应用之中使用构建器模式的情况较多。
整体来说外观模式(Facade Pattern)的适用场景可以概括为三大类:
我们需要为一个复杂子系统的组合提供一个简单的接口时,子系统们以及他们的关系通常随着业务逻辑的增长不断复杂,这个时候如果客户端代码保持和子系统直接耦合就会变成屎山代码,因此需要提供简易操作接口。
客户端程序与抽象类的实现之间具有很大的依赖性,引入外观类实际上是使用了软件工程之中几乎最重要的“间接”的思想,引入了一个新的类作为隔离接口存在,这样可以消解客户端和具体抽象实现之间的高耦合特征使开发运维变得灵活。
我们需要构建一个具有层次结构的大系统时,对于每一层的子系统或者每一个功能的一簇子系统都可以设定一个外观类形成一个Facade封装,这样能够更加清晰明了的划分系统的各个部分并且将子系统的耦合转变为Facade之间的耦合。
我们可以这样描述Facade模式的优点:
简化接口:客户端面对Facade往往不需要知道子系统的实现细节甚至是子系统之间的内部逻辑,使用统一的Facade接口即可
降低耦合:客户端代码从此不再依赖多个子系统的具体实现,而依赖Facade的抽象以及子系统与Facade之间的抽象耦合
高维护性:使用Facade层封装后的系统对外的特性由Facade统一管控,因此内部的实现细节可以更改而不会影响外部业务
高灵活性:对于部分不满足于Facade封装的功能裁剪的的用户,仍然可以越过Facade层直接使用各个子系统而不会被束手束脚
同样的使用外观模式也会引发一些问题和缺点:
Facade过载问题:如果集合了多个场景,归纳了太多逻辑在单一的Facade之中,那么Facade会变得过于庞大和臃肿,形成不必要的叠屋架梁结构反而成为了上帝类(God Object),变得难以维护和阅读。
Facade不足问题:如果客户端对于子系统的依赖没有很好的被Facade消解而是仍然存在高概率高频率的访问,那么这就归结于Facade层设计过程之中的过度简化问题,导致了Facade形同虚设。
Facade耦合问题:如果Facade和子系统之间没有良好的抽象隔离或者抽象接口,那么某个子系统或者某个子系统实现的调整会沿着调用关系反馈到Facade的代码之中甚至会影响客户端代码,形成代码整体僵化无法修改的局面。
Facade冗余问题:同一套子系统可以同时拥有多个Facade类共同构成一个Facade层,但是这些Facade之间如果存在各种功能的交叉和重复那么就会让这个子层耦合度飙升,责任混乱,引发大量的Facade代码冗余。
由于Facade本身的特性,导致其UML类图难以论述,只能如此总结:
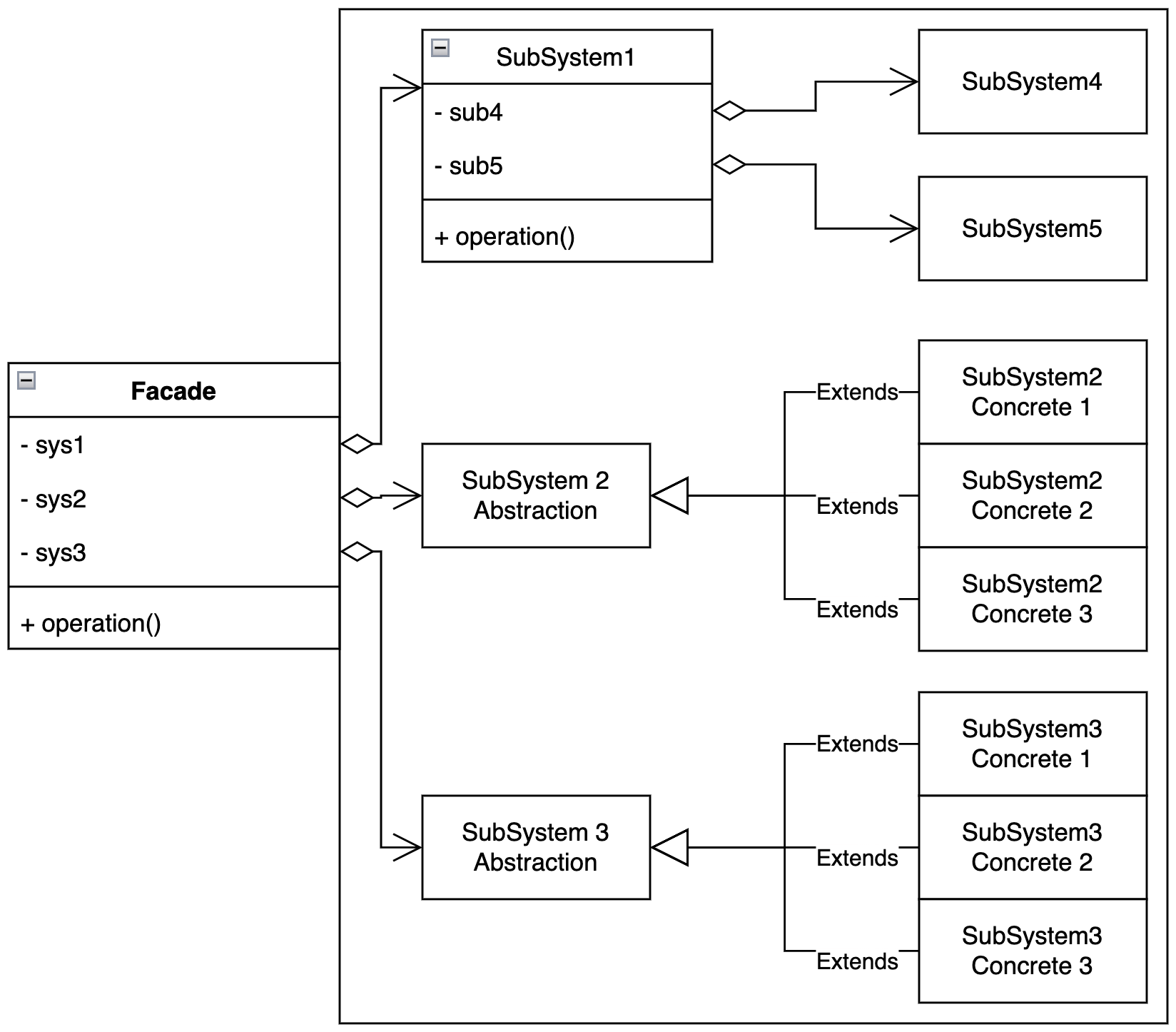
5.组合(Composite)模式
门面模式对于结构的调整实际上类似于一种对于抽象的封装而非真正的操作抽象本身的结构,然而在实际开发过程之中,我们经常碰到一些抽象的组合表征出“部分-整体”的特征并且其拓扑结构大多数呈现出树状,例如UI组件库之中既有文本编辑框这种“终端组件”也有布局、折叠区域这种”容器“,又或者某个OA管理软件之中公司的各个部门相互嵌套,最终的端点是部门的某个员工……非常自然地,我们会想到在基础的数据结构之中经常用到的二叉树结构,稍作更改就有了类似的代码:
class Node {
void addChildren(const Node* child);
void removeChild(size_t index);
Node* getChild(size_t index);
size_t getChildCount();
private:
//other member
Node* parent;
std::vector<Node*> children;
};这样我们就构建了一课树上的节点,只要构建一个根结点而后不断的将其他节点添加到根结点或者根结点的子节点的children 列表之中即可完成整个树状结构的构建。然而这种方法存在一个问题:如果使用这些代码的客户端并不区分叶子节点和分支节点那么自然无事,但是如果客户端需要区分这是否是一个叶子节点就会给客户端增加额外的判断任务,并且这种混用会让整个代码结构并不清晰明了,于是我们需要将分支节点(容器)和叶子节点(终端)从抽象的层面上区分开来:
class Container;
template<typename T>
class Component {
public:
explicit Component(T* payload = nullptr, Container* parent = nullptr)
: parent(parent), payload(payload) {}
[[nodiscard]] T* getPayload() const { return payload.get(); }
[[nodiscard]] Container<T>* getParent() const { return parent; }
protected:
Container<T>* parent;
std::unique_ptr<T> payload;
};
template<typename T>
class Container : public Component<T> {
public:
~Container() {
for (auto child : children) delete child;
}
size_t addChild(Component<T>* child) {
if (child->parent==this) return children.size();
children.push_back(child);
if (child->parent!=nullptr)
child->parent->removeChild(child,false);
child->parent = this;
return children.size();
}
size_t removeChild(size_t index, const bool destroy = true) {
if (index>=children.size()) throw std::out_of_range("Index out of range");
auto it = children.begin() + index;
if (destroy) delete *it;
children.erase(it);
return children.size();
}
size_t removeChild(Component<T>* target, const bool destroy = true) {
for (size_t i=0; i<children.size(); i++) {
if (children[i].get()==target) {
auto it = children.begin() + i;
if (destroy) delete *it;
children.erase(it);
return children.size();
}
}
return children.size();
}
Component<T>* getChild(size_t index) {
if (index>=children.size()) throw std::out_of_range("Index out of range");
return children[index].get();
}
size_t childrenCount() const { return children.size(); }
private:
std::vector<std::unique_ptr<Component<T>>> children;
};
template<typename T>
class Widget : public Component<T> {};通过以上代码我们就构建了一个区分容器和终端节点的树状结构,这是一个模版,如果我们需要便利的使用树状结构的这一特性那么我们仅需要进行模版替换即可完成任务,这种进行树状组织抽象的结构和方法就被称作组合模式(Composite Pattern)。当我们的设计过程之中出现了明显的针对于抽象而非具体实例的部分-整体层次结构,并且我们希望除了这个结构之外的功能不区分容器和节点,能够统一的被用户进行使用,那么我们就可以采用这种方式。这种模式的显著效果是:
定义了包括基本对象和组合对象抽象的层次结构,基本对象可以被组合成更加复杂的组合对象,而这个组合对象又可以进行不断的递归组合,那么任何用到基本对象
Component的地方都可以展开为一个包括Component,Container,Widget的树状结构。简化了客户端代码,客户端代码在使用这一结构的时候不需要区分也不需要关心具体的结构实现细节,并且由于使用模版或者其他相似的技术或者思路,用户对于模版类的功能使用接口绑定在
Component一层,因此完全不需要关心结构的组合逻辑。极大地提高了扩展性,组合模式能够大大的提高设计的一般性,新定义的容器或者节点能够非常容易的被添加到整个系统之中来,并且不需要后来编写者小心翼翼的遵守结构的规范而牺牲原本的功能。但是这一点也带来了一个问题,也就是新增组件的时候非常难以进行限制,当一个组件的位置上可能出现一个组件树状结构的时候,我们就不能依赖类型系统编译时结局问题而只能使用运行时的检查语句。
当我们使用组合模式(Composite Pattern)时,我们有这样几点需要注意或者可能出现问题:
显式的父组件调用:我们在
Component之中添加了parent成员,保持了从子组件到父福建的引用简化和遍历高效性,这一点引用的特性能够在后续文章的其他模式之中也看到。对于父组件的引用必须维持一个运算封闭性,也就是子组件的父组件必须是自身,因此在添加节点的addChild方法之中我们尤其检查了这一点。共享组件:共享组件的概念是当某个组件作为子组件出现在多个组件的成员之中并且被经常调用时,我们也许可以使用具有多个父组件的变体,但是这样从拓扑上整个结构会变成图状而非树状,并且对父组件的引用会引起运行上和逻辑上的双重歧义。对于这种类型其实一个好的思路是使用虚拟代理+享元模式,使用享元模式将待运算部分划分为外部状态根据传入的父组件运算,并且为了不引起解释歧义我们使用代理模式将这个结构包裹起来单独处理这部分内容。
最大化
Component接口:组合模式的目的就是是的用户对于结构之外的功能在使用时不关心它具体是一个容器还是一个节点,为了达到这一目的,其他功能的绑定应当处于顶层的Component或者干脆通过继承的关系在Component处生效,这样用户才能够随心所欲的使用除了结构之外的其他所有功能。注意树状析构:当对象通过
new或者其他什么通过堆内存分配的方式创建并且挂载到上级节点时,如果上级节点析构时并不处理这些对象的指针,就会造成后果惨重的内存泄漏,故而树状结构一定要注意析构函数和可能存在的内存泄漏问题,析构函数应当以递归的方式生效,这样当我们删除一个节点的时候就能够删除绑定在节点上的整个子树。
关于组合模式的应用,除了上文出现过的模版之外,我们这里举出一个实际应用的例子,例如我们需要构建一个文件管理系统,那么这明显具有组织层级并且需要在结构上区分叶子节点和分支节点:
//Component
class FileInfo {
public:
enum Restrict {
EXEC = 0x01,
WRITE = 0x02,
READ = 0x04
};
virtual ~FileInfo() = default;
virtual std::string getPath() const = 0;
virtual size_t getSize() const = 0;
virtual bool setRestrict(std::string& username, uint8_t code) = 0;
protected:
Timestamp createdAt;
Timestamp updatedAt;
Restrict resOwner, resGroup, resAny;
std::string owner;
std::string group;
std::string name;
};
//Container/Composite
class Directory : public FileInfo {
public:
void add(std::unique_ptr<FileInfo> component);
void remove(size_t index);
void remove(std::unique_ptr<FileInfo> component);
size_t countContent();
std::unique_ptr<FileInfo> getContent(size_t index);
//other implementation
private:
std::vector<std::unique_ptr<FileInfo>> content;
};
//Widget/Leaf
class File : public FileInfo {
public:
//other implementation
private:
std::string type;
size_t bytes;
};最后关于UML类图或者说如何概括组合模式的结构的问题,笔者并不认同GoF作出的论断,在GoF的著作之中UML类图将操作子节点的接口全部置入了最顶层的Component 类之中,虽然这样既满足了Component 接口最大甚至也能够实现用户可以在结构层面不区分容器和子节点使用,但是这里有一个显著的问题:Leaf 从逻辑上不应当有这些接口!这既不符合接口最简原则也不符合里氏替换原则,因此笔者窃以为这种对于结构的定性从某种程度上是本末倒置的追求凸显组合模式的完美而非整体设计的合理性,因此笔者给出的UML图如下:
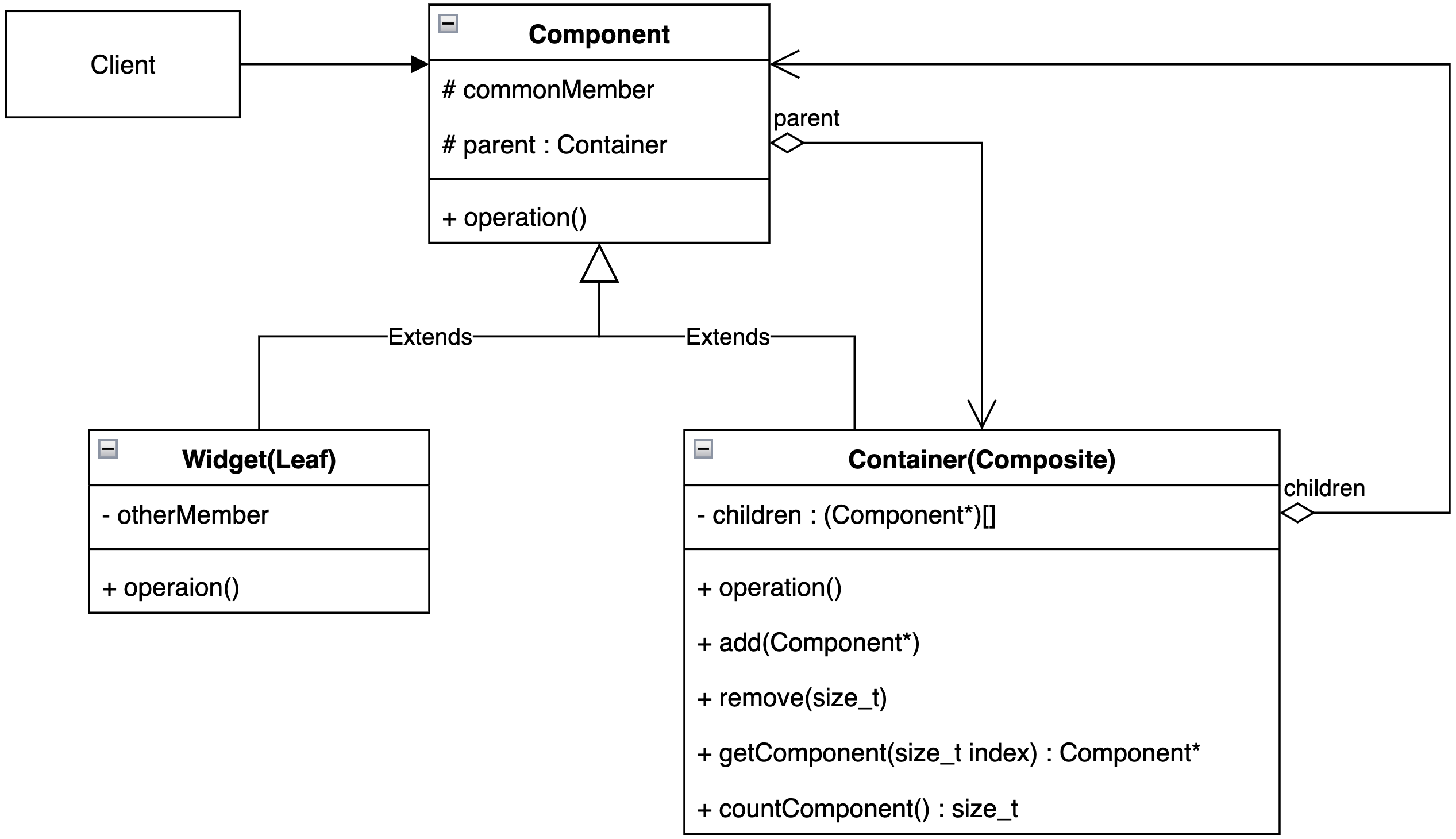
6.桥接(Bridge)模式
相比本文最后介绍的两种设计模式,前五种设计模式总有一种随意和不成气象的感觉,这是因为前五种设计方式虽然也在调整结构,但是并不是直接面向功能调整结构,而是面向场景或者使用方式调整结构,最后两种设计模式则是针对抽象的“功能”进行调整,这种调整见效快例子多并且并不会像是外观模式或者组合模式一样让人感觉“就这”——它们并不是那样的浅显。我们在经历了对于对象的访问接口进行结构调整和对于对象本身性质或者组合多个对象这样的场景进行结构调整之后接下来需要面对的是对于承担了非单一职责或者说功能变种较多的抽象进行结构调整使其满足设计原则的任务。设想这样一个场景:
假设我们目前进行一个网站开发,这是一个企业级的应用故而需要进行权限管理,例如什么样的用户能够访问什么资源而不能访问什么资源,这种访问是只读的还是可以修改的等等,那么起码我们会面临两个问题:
权限控制方式,例如ACL,RBAC,ABAC等等,决定了这个系统的权限控制按照哪种逻辑或者拓扑进行配置
权限控制存储,DataBase,LDAP,JSON等等,决定了系统权限控制信息具体存储在哪里怎样存储
假设我们按照普通的思路处理我们当然需要写一个权限控制的抽象类用于限定接口,但是这些具体的功能该怎样配合呢,写出来可能是:
class PermissionControl {
public:
virtual ~PermissionControl() = default;
virtual bool accessible(const User& user, const Resource& resource) = 0;
virtual bool canRead(const User& user, const Resource& resource) = 0;
virtual bool canWrite(const User& user, const Resource& resource) = 0;
virtual bool canRemove(const User& user, const Resource& resource) = 0;
virtual bool canCreate(const User& user, const Resource& resource) = 0;
virtual void setRead(const User& user, const Resource& resource, bool enable) = 0;
virtual void setWrite(const User& user, const Resource& resource, bool enable) = 0;
virtual void setRemove(const User& user, const Resource& resource, bool enable) = 0;
virtual void setCreate(const User& user, const Resource& resource, bool enable) = 0;
};
class PermsissionACL : public PermissionControl{
//implementation
};
class PermissionACL_DB : public PermissionACL{
//implementation
};
class PermissionACL_LDAP : public PermissionACL{
//implementation
};
class PermissionACL_JSON : public PermissionACL{
//implementation
};
//...首先说明这样的实现方式并不是不能使用,相反它拥有很好的层级划分和集成结构,是完全可用的方案——但是这太愚蠢了,设计模式解决的从来都不是能用或者不能用的问题,它解决的是屎山代码和笨蛋程序员的问题!我们观察这种形式不难总结出一些规律:
系统之中明确存在两个层级,例如上文举例的权限管理方式和权限信息存储,他们之间的功能仅仅呈现出组合上的耦合而不是抽象上的业务逻辑耦合,并且这两个层级通常可以根据谁更加接近抽象接口谁更加接近具体实现划分或者根据其他的什么标准变得泾渭分明,因此我们这里就称为基础功能分类和功能扩展分类
总的来说由于我们要将接口标准化以降低整个功能模块对外的耦合性,我们需要一个接口类,这个类是最大的抽象,用于描述整个功能模块对应的业务逻辑的操作方法和运行逻辑
假设基础功能分类有N种,那么这就决定了我们必须要根据不同的基础功能制造属于对外抽象的子类,显然他们有N个。又考虑扩展功能有M种,那么显然基础功能分类可能有对于各个方向扩展功能的不同搭配,因此每个子类又要有M个二级子类
问题开始变得惊悚起来:在不能进行简并操作的情况下对于这样一个功能模块我们要设计多少个类呢?1+N+M\times N个???这就是著名的继承爆炸(Class Explode)问题:在上方的例子之中为了完成这样一个功能我们需要写整整13个类,并且可以想见其中很多代码是完全重复的,完全没有任何复用性可言,并且假设我们对基础功能分类的某一种进行调整我们至少要调整1+M个类,这完全没有谈论耦合性高低的必要了——你不能面对完全不解耦的东西讨论耦合性……
因此我们需要抓住这种问题的核心:明显这些功能并不在同一层次发挥作用而是可以泾渭分明的区别开来,对于这种状况我们的调整方式就有了立足点:如果能够进行层切割并且使得层之间的关系是松散耦合的,例如运行时绑定或者延迟加载的多态特性,那么问题就可以大大简化下去,故而我们可以这样做:
class PermissionStorage {
public:
virtual void setPermission(const User& user, const Resource& resource, uint8_t code) = 0;
virtual uint8_t getPermission(const User& user, const Resource& resource) = 0;
};
class PermissionStorageDB : public PermissionStorage {
//database implementation
};
class PermissionStorageLDAP : public PermissionStorage {
//LDAP implementation
};
class PermissionStorageJSON : public PermissionStorage {
//json file implementation
};
class PermissionControl{
protected:
std::shared_ptr<PermissionStorage> storage;
public:
PermissionControl(std::shared_ptr<PermissionStorage> s) : storage(std::move(s)) {}
virtual ~PermissionControl() = default;
virtual bool accessible(const User& user, const Resource& resource) = 0;
virtual bool canRead(const User& user, const Resource& resource) = 0;
virtual bool canWrite(const User& user, const Resource& resource) = 0;
virtual bool canRemove(const User& user, const Resource& resource) = 0;
virtual bool canCreate(const User& user, const Resource& resource) = 0;
virtual void setRead(const User& user, const Resource& resource, bool enable) = 0;
virtual void setWrite(const User& user, const Resource& resource, bool enable) = 0;
virtual void setRemove(const User& user, const Resource& resource, bool enable) = 0;
virtual void setCreate(const User& user, const Resource& resource, bool enable) = 0;
};
class PermissionControlDB : public PermissionStorage {
//database implementation
};
class PermissionControlLDAP : public PermissionStorage {
//LDAP implementation
};
class PermissionControlJSON : public PermissionStorage {
//json file implementation
};这样以来我们就可以实现运行时绑定,例如我们使用ACL管理+Database存储:
std::shared_ptr<PermissionStorage> permissionDB = new std::shared_ptr<PermissionStorageDB>("database_name","database_password");
std::shared_ptr<PermissionControl> permissionACL = new std::shared_ptr<PermissionControlACL>(permissionDB);
permissionACL->setRead("Admin","/management",true);这样能够有效的解决我们提到的问题:
首先解决了继承爆炸的问题:当我们依旧面对一个(1,M,N)的功能结构时,我们需要书写的是两个层的接口类以及各自的扩展类,计算整个实现的总数目变为2+M+N,实现了几何级别的降阶;并且当我们需要添加一种新的扩展功能时我们只要在对应的层内添加一个类即可完成操作而不必修改对应的所有二级扩展类。
其次解决了复用性低的问题:因为代码实现了分层,所以下层实现例如
PermissionStorage的各个子类仅需要在子类内部实现一次逻辑即可在上层的PermissionControl之内遍地开花的使用而不必要进行无意义的重复,这样一来消除了修改可能引起的变动的代码数量提高了复用的代码数量,对于整个系统的开发者和维护者大大的友好。最后解决了耦合问题或者说不符合单一职责原则的问题,将整个代码分层后如果出现问题能够直接追踪到对应的层和对应的子类而不必经历文山会海的结构搜索,并且因为延迟绑定的组合形式,我们可以实现运行时调整甚至搭配CI/CD系统能够实现热切换,这样以来功能模块内部划分出弱耦合接驳点能够大大降低代码屎山出现的概率。
这种模式和思想被称为桥接模式(Bridge Pattern),同样这是一个非常具象化和好理解的命名方式,我们通过分层后在高层次的抽象层以指针的方式添加了低层次实现层的指针,这就是所谓的“桥”。归纳总结我们说在这样的场景和困境下可以考虑使用桥接模式:
整个系统的功能具有明显的层级结构,并且这种分级是结构化的,而不是面向单一方向的功能扩展的特例,非常明显的特征就是假设扩展变多就引起了继承爆炸。
我们不希望在高层抽象和底层实现之间有一个固定的绑定关系,这样的绑定关系应当是符合多态特征的,能够进行运行时切换或者灵活配置的,因此必须灵活。
对于所有层级的代码如果我们要扩展一个功能那么最省力的方式是根据该层的特性制定接口之后进行子类化而非调整整个逻辑,但是子类化的连锁反应过大会波及到其他层级的子类化并且一直扩散下去。
我们如果想要对客户端代码完全隐藏实现层的细节甚至说隐藏操作接口仅仅保留组合逻辑以构造高层对象,这时候将整个层级结构的实现模式暴露给客户端代码显然是不合时宜并且具有某种不道德性的。
当我们想要对于这种层级结构进行解耦和普适化调整使得代码复用率上升维护变简单,也就是Rumbaugh所谓的嵌套的普适性(Nested Generalization)的时候。
对于简单的桥接模式我们认为整个模式之中包含四类代码:
Abstraction,抽象层接口,决定了整个系统以何种方式进行应用,也就是获取到模块的客户端代码将会如何利用多态特性操作整个模块。
Refined Abstraction,抽象层实现,也就是Abstraction的子类,决定了抽象层定义的功能在具体的扩展或者变种方向如何实现具体的业务逻辑。
Implementor,实现层接口,决定了上层的抽象层如何调用底层代码,这个接口提供多态特性面向的是Abstraction而非单一的Refined Abstraction或者客户端代码。
Concrete Implementor,实现层实现,也就是Implementor的子类,决定了底层代码按照功能分类或者扩展变种如何具体运作以实现整个任务逻辑或者继续交付下层。
其中最重要的就是在Abstraction之中有一个指向Concrete Implementor的Implementor多态指针,它以组合而非继承也就是HAS-A的组合方式出现,这个包含关系就是桥接模式之中所谓的桥(Bridge)。我们认为桥接模式包含这些优劣特性或者说效果:
将接口与实现甚至更下层的实现部分分离,一个实现未必不变的绑定在一个接口上,他们显然具有运行时改变的特征,这有助于降低高层对于底层的编译时以来并且避免继承爆炸问题。
能够显著的提高可扩展性和可维护性,这样的组织方式大大降低了增加功能需要更改或者添加的代码数量,并且为运维人员提供了良好的排错指南降低了工作量。
这样的书写方式有些时候对于开发或者策划人员比较折磨,理解成本较高,需要准确的把握层级边界和分层点,否则容易出现更加恶劣的结果,简单的来说这种设计模式一般来说在工程的重构(Refactor)阶段展现出作用,在一开始的草稿阶段由于不是面向实现编程故而有些反直觉。
桥接模式某种程度上增加了系统的复杂度,但是复杂度的增加是为了降低其他不良特性,真正的隐患在于如果扩展不多或者层次本身不明确那么滥用这种模式非常可能导致过度设计问题的出现,通常来说这种错误的出现意味着没有正确的使用最基本的继承语法或者策略模式(以后会提到,这是一种行为类设计模式)。
需要注意的有三点:
有些时候使用C++或者其他能够实现多重继承语法的语言编程时我们也许采取组合的方式而是直接分离两个层级,客户端实现时直接编写子类继承两个层级的具体子类而非接口,这种做法有可取之处,但是这种方式从逻辑上细讲实际上是本末倒置不可能实现桥接结构。
层间管理问题:如果我们的设计逻辑之中存在剪枝情况,也就是对于N个一层功能来说不是每一个功能都能够匹配对应的M个二级功能,那么如果客户端在进行运行时绑定时使用了错误的绑定结构可能导致未定义情况的产生或者干脆搞出来一个逻辑或者现实意义上的不存在抽象,因此这种情况需要注意绑定时的错误处理。
桥退化:如果实现层只有一种实现方式,那么完全没有必要使用桥接模式,这种情况下即使层级结构存在,但是只要使用单一的实现即可完成抽象层功能那么这种实现应当直接定义到Abstraction之中而非分层,这称为桥的退化。
除了刚刚提到的桥退化问题之外,当然也有所谓的扩展桥接模式(Extended Bridge)存在也就是当实现一个模块的功能层级代码区分超过两层例如三层或者四层并且最重要的是底层代码没有理由构成一个新的有完整功能意义的模块的情况下,完全不必要写两个桥接模式,那就是本末倒置纯属鸡肋,这时候应当使用多层结构,也就是每层向下递推组合。另一种桥扩展指的是如果某个抽象层依赖两套不同的实现,那么不应当将这两套实现混为一谈而是应当各自建立实现层并且将实现接口通过组合的方式同时组合两个指针到抽象接口之中。综合举例:
我们现在构建一个实时消息传递系统,或者简单的来说是一个聊天软件,正在写这个系统之中的核心部分:
消息传输需要加密,针对不同的加密算法具有一个实现层
消息传输依赖具体的互联网协议,在裸协议之外还有保证通信的安全层
// Implementor A
class Encryptor{
public:
virtual ~Encrypt() = default;
virtual std::string encrypt(const std::string& raw) = 0;
};
//Concrete Implementor A
class EncryptorAES : public Encryptor{
//implementation
};
class EncryptorRSA : public Encryptor{
//implementation
};
class EncryptorCC20 : public Encryptor{
//implementation
};
// Implementor B2
class TransportProtocol{
public:
virtual void transmit(const std::string& data) = 0;
virtual std::string receive() = 0;
virtual ~TransportProtocol() = default;
};
//Concrete Implementor B2
class TransportTCP : public TransportProtocol{
//implementation
};
class TransportUDP : public TransportProtocol{
//implementation
};
//Implementor B1
class SecurityLayer{
protected:
std::shared_ptr<TransportProtocol> protocol;
public:
virtual void secureTransmit(std::string& data) = 0;
virtual std::string secureReceive() = 0;
SecurityLayer(std::shared_ptr<TransportProtocol> p) : protocol(std::move(p)) {}
virtual ~SecurityLayer() = default;
};
// Concrete Implementor B1
//...
//Abstraction
class Messager {
protected:
std::shared_ptr<SecurityLayer> s;
std::shared_ptr<Encryptor> e;
public:
virtual void pushMessage(std::vector<Message> msgs) = 0;
virtual std::vector<Message> pullMessage(int QoS) = 0;
virtual ~Messager() = default;
Messager(std::shared_ptr<SecurityLayer> s, std::shared_ptr<Encryptor> e)
: s(std::move(s)),e(std::move(e)) {}
};最终总结最基本的桥接模式的UML类图:
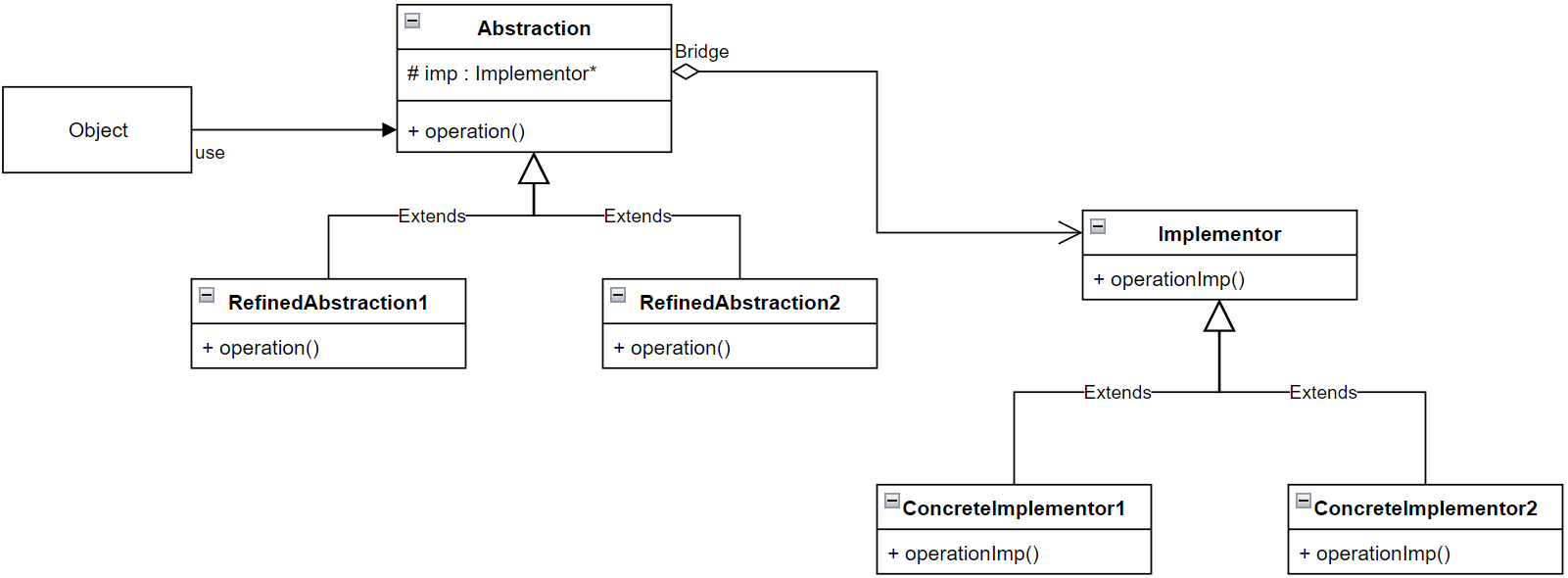
7.装饰器(Decorator)模式
至此为止看起来所有的问题都解决了,毕竟针对抽象本身功能的调整都做了,我们还讨论的桥接模式的横向扩展和纵向扩展,看起来已经至臻圆满大道可成了,但是问题就出现在这个桥接模式的硬性要求”可分层的功能“上,这时候有朋友可能会说既然已经说了分层的怎么处理,而且又指出了不分层或者层次模糊的功能扩展不能通过结构处理那么还有什么可谈的呢?我们仍然有最后一层可悲的厚障壁没有解决,不解决这个问题继承爆炸还是如影随形——你修改代码而用不了桥接模式的样子简直就是闰土和瓜田里的猹。来看这样一个经典例子:
我们目前要编写一个处理数据流(Stream)的模块,可能被处理的信息流主要有这几种:
二进制信息流BinaryStream
字符串信息流StringStream
文件类信息流FileStream
别急,没完:这些信息流还要做一些操作:
由于带宽宝贵,我们可能要进行压缩Compressed
由于通信安全,我们可能要进行加密Encrypted
由于数据冗长,我们可能要进行缓存Buffered
由于运维要求,我们可能要日志化输出Logged
各位学习过桥接模式的闰土此刻兴奋的举起了手中的叉子,这个我会:
制定一个
Abstraction叫做Stream,对应三个不同的RefinedAbstraction叫做BinaryStream……制定一个
Implementor叫做Streamperation,对应四个不同的ConcreteImplementor叫做Compressed……在
Stream之中挂载一个protected指针指向多态接口StreamOperation完工!
那么猹现在要跑出来吃瓜了,请你实现这样的功能:
我不想要信息安全,文件也很小,也不要压缩,驱动够硬不要日志,就给我一个
FileStream吧!我又要信息安全,传输内容还很大,企业内容需要保密,还要输出日志,来一个
EncryptedBufferedLoggedBinaryStream!
可怜的闰土举起了叉子拔剑四顾心茫然,这第一个要求还好,加上一个空指针判断在各个操作里面就好了!这第二个,等会儿,不是!情况不对啊,为什么第二层的狗东西们还能拼起来啊!!这命名长度已经快让分屏的编辑器折行显示了!!!嗯,看起来不能够使用桥接模式,嘶那么就只能按照公式1+N+M*N=16写了,等等不对,我这次要写的是76个类????这就关系到层级关系的另一种方式了:假设一个层内的功能并不是一个单选而是一个多选(容许全选或者全不选)那么该怎么办呢?我们不妨总结一下这两种重要的区别:
如果考虑目前共有两个分层,其中一个是实现层一个是抽象层,各有M和N个选择并且只能单选,就像是上一小节之中的最后一个例子种的传输层协议,你不可能对一条信息既要选择TCP协议又要选择UDP协议,而且二者有依赖关系不可能脱离实现层单独运作抽象层,那么我们可能出现的类只有1+N+M\times N个并且可以安心挂载桥接指针不必考虑指针不作用的情况。
目前还是有两个分层,但是其中一个占据主要地位,一个占据次要地位,主要地位的功能能够独立工作但是次要地位对应的功能不可能脱离主要功能工作:明显一个无内容的纯抽象的东西没法压缩加密之类的吧?但是次要功能层出现了非常恶劣的操作——他们可以相互组合并且这种组合没有具体数量限制,那么公式的计算就变成了1+N+N\times M!
这样就要用到本小节介绍的装饰器模式(Decorator Pattern),这种模式作用的显著特征就是两个代码层不再是依赖关系而是主体+附着操作的关系并且附着操作可以互相拼接(至于拼接有顺序的话那么就是更加复杂的情况了,那么就要考虑到更加复杂的设计模式之间互相组合的状态了,这里不做讨论)毫无约束。那么我们在进行抽象的时候不妨这样做,从抽象本身划分时就考虑到附着问题,对于附着层单独抽象:
class Stream {
public:
virtual void* read(size_t &length) = 0;
virtual size_t write(void* data,size_t length) = 0;
virtual void* seek(size_t index) = 0;
virtual void start() = 0;
virtual void close() = 0;
virtual ~Stream() = default;
};
class DecoratedStream : public Stream{
protected:
std::shared_ptr<Stream> stream;
public:
DecoratedStream(std::share_ptr<Stream> s):stream(std::move(s)) {}
};对于主体性的操作我们这样子类化:
class FileStream : public Stream {
private:
std::string path;
File file;
public:
void* read(size_t &length){
//try read <length> data from file
}
//other implementation
};
class BinaryStream : public Stream {
// binary data version implementation
};
class StringStream : public Stream {
// string data version implementation
};而对于附着类的操作也就是所谓的“装饰操作”我们这样子类化:
class EncryptedStream : public DecoratedStream {
private:
Algorithm algorithm;
long long salt;
public:
void* read(size_t &length){
//cancel encryt before other operation
stream->read(length);
}
size_t write(void* data,size_t length){
//encrypt data before other opeartion
stream->write(data,length);
}
};
class CompressedStream : public DecoratedStream {
// compress opeartion attached
};
class BufferedStream : public DecoratedStream{
// buffer operation attached
};
class LoggedStream : public DecoratedStream {
// logging operation attached
};这样操作之后我们可以这样完成前文的两个桥接模式无法解决的需求:
// file stream without decoration
std::shared_ptr<Stream> fs = std::shared_ptr<FileStream>("./data/text.txt");
auto data = fs->read(100);
// stream with several decoration
std::shared_ptr<Stream> encryptedBufferedLoggedBinaryStream = std::shared_ptr<EncryptedStream>(
Encrypt.SHA256,Math.random(),std::shared_ptr<BufferedStream>(
1024, Buffer.OverFlowCover, std::shared_ptr<LoggedStream>(
"./log/tmp/test.log", Logger::WARNING, std::shared_ptr<BinaryStream>()
)
)
);我们的思路就是:对于不需要附着的操作,我们使其直接继承本层接口子类化,正常进行子类化实现正常进行多态使用即可。对于有附着操作的对象我们采用一种组合的方式,将被装饰的对象作为指针传入成员之中,子类化时通过调用其原本的函数形成嵌套附着关系,对于多个装饰操作使用多态特征的嵌套化初始化就会实现对应函数的嵌套化运作功能。这样的书写方法被称作装饰器模式(Decorator Pattern)或者打包器模式(Wrapper Pattern),我们可以归纳总结出使用这种模式的条件:
分层时出现两种不同的层,他们之间有单向依赖关系,被依赖功能可以独自行驶职责但是依赖者可能出现无规律无约束的不可预测的组合方式
附着操作应当是不影响其他对象的情况下进行的,也就是说附着操作不能够对后续可能发生的其他附着操作产生破坏多态特征的处理工作
附着操作可能是单向的或者是包裹性的,包裹性操作例如将数据先解密等待主体操作或者其他附着操作完成后在进行加密,也就是这种操作可以是可撤销的
附着操作后的对象应当符合主体对象的特征,也就是说装饰器模式的显著特征就是在装饰接口管辖下的类对于主体类而言既有IS-A继承关系也有HAS-A组合关系
装饰器模式不通过继承达成构建对象和产生有意义操作的目标,它通过运行时嵌套组装甚至动态调整完成目标对象的构建、使用、运行时动态调整
在装饰器模式之中可以划分出这样几类数据类型的抽象:
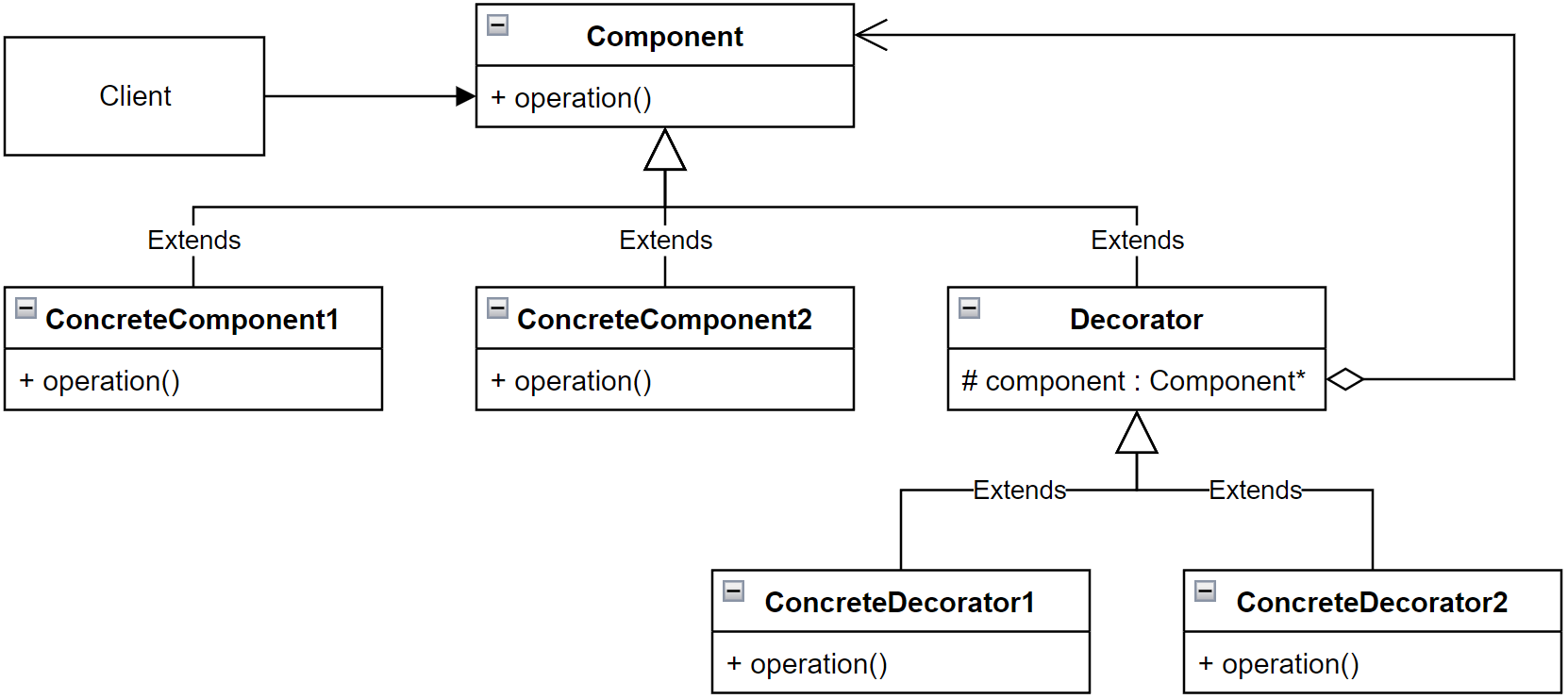
Component,模块整体的接口,也就是主体功能对应的数据结构应有的操作接口,这个对象接口应当作用于整个模块之中的所有类提供多态特性和统一的操作接口,这个接口应当作为装饰器接口的基类出现
ConcreteComponent,模块处理对象的主体操作的子类,这些类直接继承抽象接口类Component,主体层的扩展或者变种功能应当在此实现,他们可以独立运行发挥功能而不同于桥接模式的抽象层无法独立工作
Decorator,附着性操作的接口,用于和Component进行区分,不要向Component之中添加多余的指针成员造成职责混乱,此接口的主要功能是组合Component类的指针形成典型的IS-A+HAS-A双结构,这是装饰器模式的核心特征
ConcreteDecorator,附着性操作的子类,各个不同的附着性操作应当在这些子类之中实现并且在重构函数时以调用的形式执行指针指向的对象的操作形成嵌套结构支持最终的动态装配和动态调整功能的作用
装饰器模式具有两个主要的优点和缺点:
优点1:比静态继承更加灵活,与多重继承相比装饰器模式提供了更加灵活的向实例对象添加职责和去除职责的方式,能够显著的利用多态特征,并且这种添加可以是重复的,只要用两次相同的装饰器即可
优点2:避免在层次结构高层的类过复杂,装饰器模式避开静态继承之后本质提供了一种热插拔的方式调整对象的结构和功能,这就保证了系统之中的各个子类保证单一职责不会产生复用率低和耦合度高的代码
缺点1:Decorator相比于Component来说略有不同,事实上前者给后者添加了一层近乎于透明的包装,如果我们从多态特性的角度出发即使是使用了附着操作的对象也不应当按照Decorator接口使用多态而是应该按照Component接口使用。从这一点上来说给客户端的开发者增加了一些不必要的注意事项。
缺点2:产生小对象,这种设计模式进行系统设计的时候由于不怎么约束附着操作的顺序和相容性,可能产生一些功能相同但是定义写法不同的非常类似的小对象,这就要求模块的客户端使用者较为了解装饰器的每个附着操作才能良好使用。
使用时需要注意的四点:
保证接口的一致性,Decorator对应的子类必须能够以IS-A的方式匹配Component否则将会造成嵌套职责代码的失效或者未定义行为
保持Component的简单性和超然性,如果需要调整整体功能不应当调整Decorator而是应当调整Component,前者应当作为透明包装存在;而如果需要调整的功能不作用于抽象整体那么应当直接调整对应的操作的子类而不是调整接口
注意使用条件避免过度设计,如果附着操作层的附着性不明想或者附着操作非常少甚至单一,那么没有必要使用装饰器模式,这只会增加系统的复杂度而不能够达成通过重构进行代码结构优化的目的。
装饰器模式专注于处理附着操作特征的分层功能,这与桥接模式并不冲突,如果一个系统之中既有严格依赖关系的功能分层也有附着层(较为常见)那么应当同时使用桥接模式和装饰器模式,他们之间不存在竞争排他关系。
最后总结装饰器模式的UML图:
8.总结
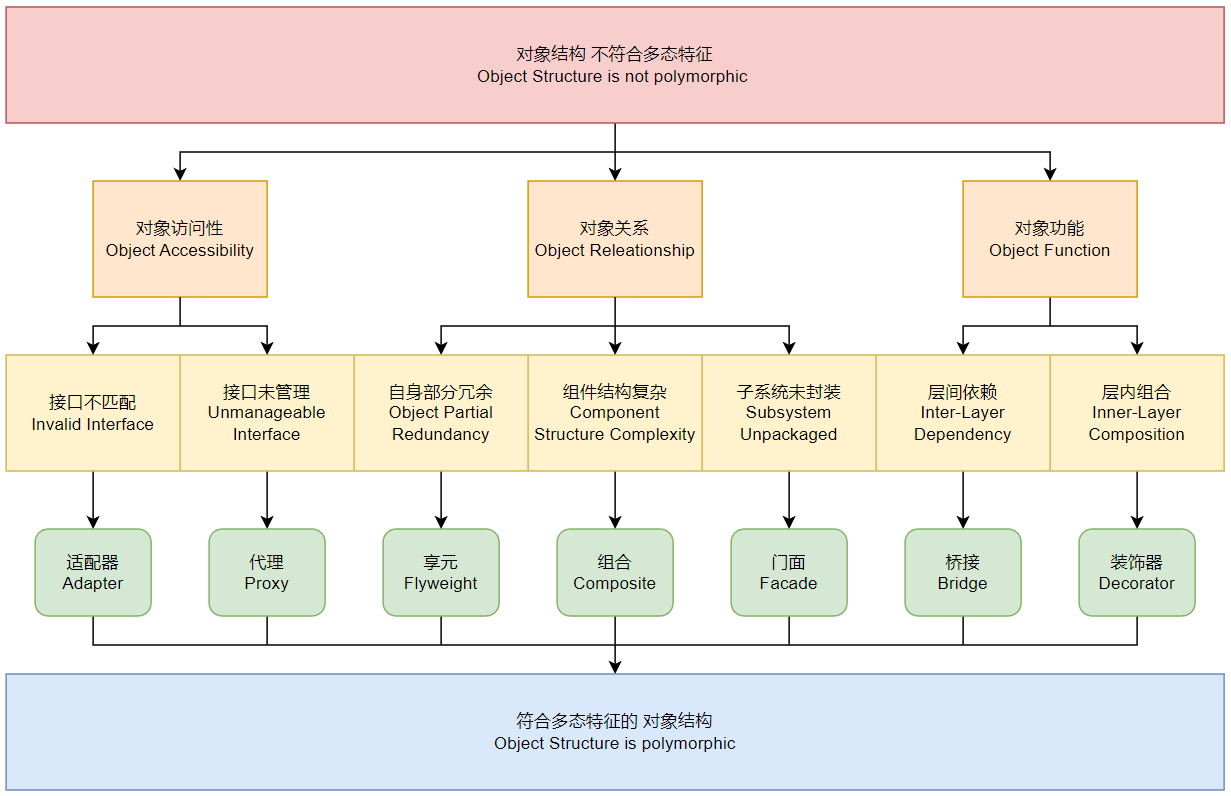
结构型设计模式主要用于解决类或对象之间的结构问题,使系统更灵活、可扩展、可维护。这张图从对象访问性、对象关系和对象功能 三个角度分析了结构问题,并引出了七种结构型模式,整体解决问题的重点是对象结构不符合多态特征:
对象访问性(Object Accessibility)
问题:接口不匹配(Invalid Interface):某些组件的接口不兼容,导致无法直接使用——方案:适配器模式(Adapter):用于接口不匹配的情况,使原本不兼容的接口可以协同工作
问题:接口未管理(Unmanageable Interface):某些对象的接口过于复杂,难以直接使用——方案:代理模式(Proxy):为对象提供一个访问控制层,用于管理对象的访问,如远程代理、虚拟代理等
对象关系(Object Relationship)
问题:对象自身部分冗余(Object Partial Redundancy):某些对象的数据或状态在多个实例间重复存储,占用过多资源——方案:享元模式(Flyweight):减少对象实例的数量,共享状态 以减少内存占用
问题:组件结构复杂(Component Structure Complexity):系统中的组件关系复杂,层次嵌套较多,不易管理——方案:组合模式(Composite):将对象组织成树状结构,使客户端可以一致地对待单个对象和对象的组合
问题:子系统未封装(Subsystem Unpackaged):子系统的调用细节暴露给了外部,导致客户端依赖过多,难以维护——方案:门面模式(Facade):为复杂的子系统提供一个统一的接口,简化客户端的调用,降低耦合性
对象功能(Object Function)
问题:层间依赖(Inter-Layer Dependency):不同层次的组件之间相互耦合,导致难以扩展——方案:桥接模式(Bridge):解耦抽象和实现,使它们可以独立变化,适用于多个维度变化的情况
问题:层内组合(Inner-Layer Composition):普通分层无法解决的的功能不够灵活,可能需要支持动态扩展功能——方案:装饰器模式(Decorator):动态地扩展对象的功能,而无需修改原对象代码,适用于功能扩展的场景