

——从设计模式提高开发水平02
在所有的GoF23种设计模式之中有5类设计模式的作用机制产生于“创建一个抽象的具体实现”阶段,也就是将类对象进行实例化的阶段。这些设计模式从构造目的上分为一类:创建型模式(Creational Pattern)。有时候我们的业务逻辑的抽象程度很高而对应的实现手段或者实现场景非常复杂多变或者我们需要严格控制抽象到实现的流动的情况下我们就需要从创建对象的“根源步骤”去构造系统,并且其他的设计模式在现实业务场景之中或多或少需要与创建类设计模式进行组合。
0.创建类设计模式综述
在GoF23种设计模式之中可以分为三大类别:创建型模式,结构型模式和行为型模式。本文涉及的五种模式主要关注对象的创建过程,它们通过封装实例化过程的具体逻辑和接口帮助开发者在构造对象的时候更加灵活的适应系统变化,减少代码耦合度,提高可扩展性和可复用程度。这些设计模式的主要用途可以总结为以下几点:
将对象的创建过程与使用过程解耦分离:避免在代码之中使用
new操作符,这个操作符在非常多的场景下会导致强耦合,甚至到了影响面向对象多态继承特性的程度,故而避开这个操作符本身就是分离创建对象(实例化)过程的某种指标。支持复杂对象的灵活构建:对于结构复杂的对象,例如说含有多个复杂子组件并且根据场景需要进行不同的组合,可以实现分步骤、逻辑灵活、结构清晰的构建实例化过程。这样能够书写过多的创建代码或者创建过多冗杂繁复的构造器并且在构造器中填入许多重复代码的问题。
控制具体实现层面数据的流动性:某些抽象的实例化需要满足特定的条件或者按照某种特定的方法进行控制,例如限制实例数量、延迟加载等等,在这种情况下严格的将对象实例化的过程管控可以实现精细化的数据流动管理。
创建型设计模式通常不会单独出现,而是通过封闭实例化过程但是开放对象具体实现和使用过程的方式与其他的设计模式进行组合使用,主要特点包括:
封装对象创建过程:将具体对象的创建逻辑隐藏在某个类或者方法之中,形成一套逻辑接口,用户无需关心对象的构造细节,关注点仅仅在于对象的使用。
支持复合对象的创建:支持分步骤的、分解过程的创建复杂的符合对象,简化复杂对象的创建逻辑,复用不同方式之中共同范式的创建代码,从而将创建实例的过程也实现抽象。
解耦对象的创建过程:将具体对象的业务逻辑分层为创建阶段和使用阶段从而分离出创建部分并且封装,减少对象创建对系统整体的影响,提高复用性降低耦合性。
1. 单例(Singleton)模式
在现代软件的构建之中不少情况下会碰到这样的情况:某些数据和操作对整个软件来说是“全局的”,也就是其生命周期基本上与整个软件的运行生命周期相当,其使用范围和作用对象广泛的分布于软件的各个部分之中。例如我们现在要开发一套MQTT客户端,可能同时连接多个服务器订阅/发布多个主题,那么就需要一个全局的MQTT客户端管理器,保存各个客户端的参数和实例,这些客户端共同使用管理器的方法和配置,并且可以通过管理器对各个客户端链接进行寻址和生命周期控制。
在这种背景下我们不免有这样的疑问:既然这些数据是全局的,为什么不可以变成一大堆堆内存之中的全局变量?既然这些操作也是全局的那么为什么不能变成一大堆游离的全局函数?如果说一定要利用到面向对象的语言特性的话为什么不可以写一个类但是其中全部都是静态成员变量和静态方法?基于以下四点考量我们不能这样做:
可维护性差:全局变量和全局函数很难集成到一个源代码文件之中书写,会散布在代码的各个部分之中,难以追踪其状态变化并且修改起来费心费力容易出现BUG,并且这样会极大增加测试和运维人员的工作量。
线程不安全:全局堆变量和函数的初始化需要二外的线程同步控制,在书写的过程种需要时时注意考量多线程操作的可行性,例如函数的可重入性,否则在多线程环境之中可能出现竞争问题。
扩展性不足:全局变量无法方便地进行例如延迟初始化这样的操作,也不支持定制初始化行为,并且由于非面向对象或者全静态等编写方式在与其他模块接驳时可能引入兼容性问题或者转换代码引起效率下降。
全局污染:全局变量会污染命名空间,增加命名冲突的风险,如果要改变这种状况就要额外制定命名规则并且极大可能引入冗长繁复的前缀或者后缀。变量在程序结束时极可能出现无法正确销毁的情况,引起内存或者信息的泄露。
那么针对这种模式的应用场景,我们这样规定单例模式(Singleton Pattern)的基础设计目标:
在系统的一个运行实例之中只允许同时存在一个类对象的实例
这个对象的实例应当具有一个公共方法作为访问接口,并且能够兼容面向对象语法
对象实例的创建/销毁代码应当进行保护以避免不当使用
以上所有目标应当封装良好,对用户屏蔽实现细节并且使用户免于多余的设计考量
针对以上几个简单而且基础的目标我们可以编写单例模式的最简单实现:
//类定义
class Singleton {
//other codes
public:
void sampleMethod();
//提供访问唯一实例的公共方法
static Singleton* getInstance();
//屏蔽对象实例拷贝以获取额外对象的路径
Singleton(Singleton const&) = delete;
//屏蔽对象实例通过赋值以获取额外对象的路径
Singleton& operator=(const Singleton&) = delete;
private:
//全局唯一实例对象的挂载指针,指针本身无法直接访问
static Singleton* instance;
//屏蔽构造器以管控实例对象的创建行为
Singleton();
//屏蔽析构器以管控实例对象的销毁行为
~Singleton();
};
//实现
Singleton* Singleton::instance = nullptr;
Singleton *Singleton::getInstance(){
if(instance == nullptr){
instance = new Singleton();
}
return instance;
}
Singleton::Singleton() {
//do sth. in constructor
}
Singleton::~Singleton() {
//do sth. when destruct
}
void Singleton::sampleMethod(){
std::cout<<"This is a sample function"<<std::endl;
}
//用例
Singleton* singletonInstance = Singleton::getInstance();
singletonInstance->sampleMethod();可以看到通过如上的代码我们实现了:
屏蔽构造器为
private这样既能够占位编译器默认的构造器又能够使得任何new创建实例的行为无法通过编译屏蔽引用复制和赋值运算符,断绝了通过既有实例复制的方式获得额外实例的可能性,避免意外的实例隐式创建
屏蔽析构器为
private如同屏蔽构造器一样使得任何显示析构全局实例的做法无法生效提供了全局唯一实例
Singleton* Singleton::instance作为挂载点,通过这个指针可以访问唯一的实例,然而它又是private屏蔽的,因此无法通过除了getInstance()之外的任何手段获得这个指针
这里很多教科书在强调一个笔者看来是伪概念的东西:
饿汉模式:当系统启动时马上进行全局实例的加载,也就是将全局指针一开始就挂载一个实例
饱汉模式:当全局实例第一次被调用时创建,也就是上文之中代码的写法
笔者认为这是一个伪概念的原因在于:饿汉模式实际上就是当系统启动时执行getInstance() 的饱汉模式,二者除了在创建全局实例的时间点上有所不同之外没有任何的不同,饱汉模式本身是饿汉模式的一种超集,我们在进行抽象设计的时候应当考虑超集而非子集。并且,饿汉模式引入了这样一种假设:在系统启动时直接创建实例不会带来什么不良影响,但是这样取代用户做决定的做法在笔者看来反而破坏了设计模式这一领域的核心理念,引入了具体实现而非停留在抽象层面。
以上代码有两个重要漏洞:
因为屏蔽了析构器,我们无法使用
delete关键字析构实例,创建的实例也不会在程序退出时自动销毁,这就造成了内存泄漏getInstance()函数本身是线程不安全的:假设目前有两个线程A&B,当A优先试图获取实例时它注意到实例并未创建,但是当A对全局指针进行非空判断准备创建实例时B获取到执行优先度;由于此时A并未完成创建动作,因此实例指针仍然是空,因此B也开始进行实例创建,那么我们会发现实例指针在A和B线程之中分别被new挂载了两次,后一次的挂载会覆盖前者,前者的内存空间就泄露掉了。
我们给创建动作加上一个锁:
class Singleton {
//other codes
public:
static Singleton* getInstance();
Singleton(Singleton const&) = delete;
Singleton& operator=(const Singleton&) = delete;
private:
static Singleton* instance;
//加入创建锁
static std::mutex lock;
Singleton();
~Singleton();
};
Singleton* Singleton::instance = nullptr;
//静态创建锁实现
std::mutex Singleton::lock;
Singleton *Singleton::getInstance(){
lock.lock();
if(instance == nullptr){
instance = new Singleton();
}
lock.unlock();
return instance;
}
Singleton::Singleton() {
//do sth. in constructor
}
Singleton::~Singleton() {
//do sth. when destruct
}这样看起来就完成了多线程安全的问题,但是这就引入了巨大的代价:假设我们目前编写的是一个Web服务器的后端软件,那么在高并发的状况下,可能每秒访问这个全局实例的需求是几百上千的频率,那么频繁的进行上锁-解锁-等待的循环就严重影响了代码执行效率。然而我们发现引起线程不安全的仅仅是实例的创建阶段,一旦实例创建后这个getInstance() 方法将会仅仅存在读取动作而不存在写入动作,我们都知道如果资源是只读的,那么并发操作是不会引发冲突和资源竞争问题的,因此我们这样改造行不行呢?
Singleton *Singleton::getInstance(){
if(instance == nullptr){
lock.lock();
instance = new Singleton();
lock.unlock();
}
return instance;
}看起来非常美好,但是这是相当愚蠢的操作方式。还是假设有线程A&B,目前的状况是A和B在初始化阶段都通过了空指针的判断,A首先拿到锁完成了实例初始化挂载,A解锁后我们就发现了意外状况:B此时已经处于if 判断语句之中,A一旦解锁B就会拿到锁并且重新进行初始化挂载——实例又创建了两次!那么我们需要引入一个二重判断锁:
Singleton *Singleton::getInstance(){
if(instance == nullptr){
lock.lock();
if(instance == nullptr) instance = new Singleton();
lock.unlock();
}
return instance;
}在这个代码之中我们还是考虑上文的状况,发现不同:当A解锁之后B获取到锁,重复判断instance 指针是否为空,发现此时指针已经被线程A挂载了一个对象分配了内存空间无法通过空指针判定,于是放弃初始化直接返回A初始化后的对象——锁的作用正常生效并且线程安全。但是问题并没有解决,我们需要面对内存Reorder问题。现代处理器架构之中大多数使用流水线架构(说了不懂硬件的软件工程师是XX)因此很多编译器在编译高级语言为机器码的时候会引入语义一致性结构上的指令重排序:不影响一个语句最终的执行结果但是对其中的分解步骤进行重新排序。那么对于instance = new Singleton():
我们期望的顺序:分配内存空间->执行构造器->将内存空间挂载到指针
实际可能的顺序:分配内存空间->将内存空间挂载到指针->执行构造器
在第二种顺序之中,假设AB目前都通过了外层的空指针检测,A优先获取到锁,开始按照顺序二执行代码,当内存挂载到指针后赋值语句已经完成,但是这时候构造器没有执行完毕,指针指向了一篇尚未初始化后的内存空间,A释放锁,等待调用这片内存的时候才完成初始化,这对于A这个单线程来说确实不影响语义一致性检测,编译器所作所为是合理的。但是问题出现了:当A释放了锁之后B拿到锁,进行二次空指针判断的时候发现内存已经分配,于是不进行初始化,而B相比于A更早的使用了实例,于是发生了实例未初始化的运行时错误!!
要解决这个问题需要一点点的额外操作,有的朋友可能马上想到使用volatile 修饰指针,但是这个关键字无法从CPU原子指令的层面上控制代码执行顺序,它只能够禁止编译器优化某一变量或者某一单一操作,对于复合操作和指令重排无能为力。我们可以通过标准库之中的原子指令库实现这一功能:
class Singleton {
//other codes
public:
static Singleton* getInstance();
Singleton(Singleton const&) = delete;
Singleton& operator=(const Singleton&) = delete;
private:
//原子变量禁止重排序
static std::atomic<Singleton*> instance;
static std::mutex lock;
Singleton();
~Singleton();
};
//原子变量指针实现
std::atomic<Singleton*> Singleton::instance(nullptr);
std::mutex Singleton::lock;
Singleton *Singleton::getInstance(){
//定义一个指针tmp从内存之中读取instance
Singleton* tmp = instance.load(std::memory_order_relaxed);
//控制指令顺序,分离加载和存储操作,确保后续的读写操作绝不会重排到这个屏障之前
std::atomic_thread_fence(std::memory_order_acquire);
//一层空指针判断
if (tmp == nullptr) {
//在当前if分支内上锁,脱离if分支后自动释放
std::lock_guard<std::mutex> guard(lock);
//为了内层空指针判断二次读取
tmp = instance.load(std::memory_order_relaxed);
//内层空指针判断
if (tmp == nullptr) {
//初始化
tmp = new Singleton();
//分离操作屏障,确保构造函数完成于这个屏障之前
std::atomic_thread_fence(std::memory_order_release);
//完成存储动作
instance.store(tmp, std::memory_order_relaxed);
}
}
return tmp;
}
Singleton::Singleton() {
//do sth. in constructor
}
Singleton::~Singleton() {
//do sth. when destruct
}不过,如果我们的开发环境支持C11标准,那么有更加简单的方式,因为C11开始支持局部静态变量(当然也是堆变量)的初始化线程安全,只不过我们返回的就不是实例指针而是实例引用了:
class Singleton {
public:
static Singleton& getInstance() {
static Singleton instance; // 静态局部变量,线程安全
return instance;
}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
private:
Singleton() = default;
~Singleton() = default;
};而且在这种情况下单例的销毁也不是问题:当程序结束时局部静态变量instance 会自动被GC,这时候编译器将通过引用本身调用析构器因此修饰符private 并不会阻止这个过程,从而能够将实例安全的销毁而避免内存泄漏问题。然而这样的作法会让整个单例机制的可扩展性下降并且引起某种程度上的耦合性提升,我们最终使用std::shared_ptr 和std::once_flag 解决这一问题:
template <typename T>
class Singleton {
public:
template <typename... Args>
static std::shared_ptr<T> getInstance(Args&&... args){
std::call_once(initialized, [&args...](){
instance = std::shared_ptr<T>(
new T(std::forward<Args>(args)...), [](T* p) {
delete p;
});
});
return instance;
}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
protected:
Singleton() = default;
virtual ~Singleton() = default;
private:
static std::shared_ptr<T> instance;
static std::once_flag initialized;
};
template <typename T>
std::shared_ptr<T> Singleton<T>::instance = nullptr;
template <typename T>
std::once_flag Singleton<T>::initialized;通过以上的代码:
创建一个模板基类
Singleton可以被子类通过模板继承,这样子类就有了单例特性,实现了低耦合度的抽象分离将默认构造器设置为
protected禁止直接通过构造器构造实例对象的目的,当然子类不要作死非要写一个public构造器将默认析构器同样设置为
protected并且设置为虚函数便于子类重载默认析构器,同样的子类不要作死public析构设定一个全局唯一实例挂载点
static std::shared_ptr<T>这样就可以应用智能指针的众多优秀性能设定一个一次性标志位
static std::once_flag initialized这样就可以保证线程安全和重排序安全的进行实例创建同样删除了赋值运算符和引用复制的默认方法,避免意外的实例创建发生
代码的核心方法是实例获取方法
getInstance通过一次性执行锁
std::call_once保证只进行唯一一次实例创建并且保证线程安全和重排序安全没有添加额外的线程锁,创建实例后
initialized标志位会阻止之后的任何创建动作通过可变参数模板
Args&&... args实现了子类扩展构造器的可能性,应对更加复杂或者分步骤的实例化创建由于
instance是一个智能指针,在任何作用域之中释放实例挂载指针都不会导致其错误的释放实例导致意外销毁通过一个Lambda函数实现了当应用程序代码执行完毕时
instance可以通过reset()方法调用该函数实现析构,从而避免了当模块或整个程序执行完毕时产生资源/内存的泄露问题
任何想要使用该单例模式的类可以这样写:
//模板继承
class MySingleton : public Singleton<MySingleton> {
public:
//other codes
//子类扩展代码可以随意添加
void sampleFunction(){
std::cout << "This is a Sample Funcion of class MySingleton" << std::endl;
}
friend class Singleton; //友元Singleton类保证父类能够访问子类protected或者private的构造器/析构器
protected:
MySingleton() {
std::cout << "This is overrided default constructor" << std::endl;
}
//更多参数的构造器
explicit MySingleton(cosnt std::string& name){
std::cout << "This is extended consturctor with name: " << name << std::endl;
}
~MySingleton() override {
std::cout << "This is overrided default desturct method" << std::endl;
}
};
//子类使用范例
auto mySingleton = MySingleton::getInstance("Test Name");
mySingleton -> sampleFunction();最终我们可以用这样一种UML类图来描述单例模式:
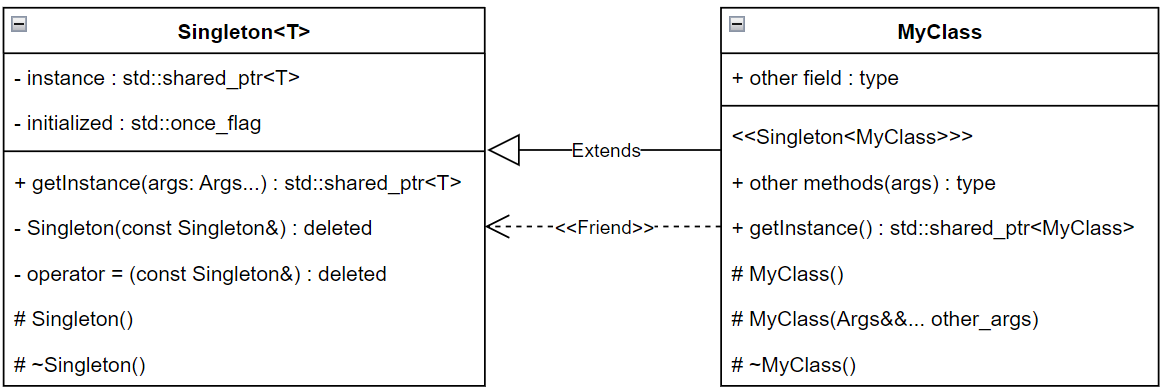
2.工厂方法(Factory Method)模式
单例模式是非常好理解的从面向过程的全局变量+方法过渡到面向对象软件设计的一类模式,不同于前者,工厂模式乍看起来有些”过度设计“的冗余感,尤其是对于刚脱离科班没有什么编码经验的开发者,这个模式的理解和使用并不那样的直观明确。这里笔者选择不在一开始就提出问题和解决方案而是通过一个笔者认为非常具有代表性的案例来切入:
假设目前有这样一个业务需求:开发一套UI组件用于制作图形交互界面
这套UI组件应当能够与底层数据业务代码分割,形成一个单独的UI显示层,所以它应当是面向对象并且提供操作接口的
这套UI组件应当包含常用的图形化界面控件例如按钮
Button文本视图TextView等等,这些控件应当构成一个整体这套UI组件在PC机层面应当是跨平台的,例如支持Windows系统、MacOS系统、Linux下的GNOME桌面等等
让我们首先书写一个按钮Button 类,仅仅考虑Windows,MacOS,Linux三种情况:
class Button {
public:
explicit Button(const GraphicContext& context = nullptr):context(context) {};
Button(const GraphicContext& context, ...):context(context){
//do sth. when construct Button object
}
void onClick(){
//callback function when click this button
}
void onDraw(){
//callback function when draw this button on canvas
}
//other codes
private:
GraphicContext context;
//other codes
};看起来这个类可以非常简单的构造出来,但是当我们具体实现其中的方法例如onDraw 的时候就会常见这样的组合逻辑:
void Button::onDraw(void){
if(context.systemName.equals("windows"){
//draw button when under Windows
}else if(context.systemName.equals("darwin"){
//draw button when under MacOS
}else if(context.systemName.euqals("linux"){
//draw button when under Linux
}else throw std::runtime_error("Unsupported Platform");
}虽然这样的代码非常常见,然而这就是”代码屎山瘟疫“滋生的病灶,例如:
如果有数个这样的函数例如
onDrawonClick这样的十几个函数,那么这种判断逻辑需要书写十几次?如果现在由于使用的底层图形驱动代码变更,要区分Windows7,Windows10,Windows11等系统,并且后续还要加入其他类型的操作系统或者图形环境的支持,那么是不是需要不断地改动这个
Button类,这个类会多么臃肿?
于是我们常见的处理屎山代码进行重构的思路就是:将与具体实现绑定的组合逻辑运用抽象的方式分离。例如:
class Button {
protected:
GraphicContext context;
public:
Button(const GraphicContext& context):context(context){};
explicit(const GraphicContext& context, ...):context(context){};
virtual ~Button() = default;
virtual void onDraw() = 0;
virtual void onClick() = 0;
};
class ButtonWindows : public Button {
public:
explicit Button(const GraphicContext& context):context(context){
//constructor under windows
}
void onDraw() override {
//draw method under windows
}
//other codes
}
class ButtonDarwin : public Button {
public:
explicit Button(const GraphicContext& context):context(context){
//constructor under MacOS
}
void onDraw() override {
//draw method under MacOS
}
//other codes
}
class ButtonLinux : public Button {
public:
explicit Button(const GraphicContext& context):context(context){
//constructor under linux
}
void onDraw() override {
//draw method under linux
}
//other codes
}
//应用实例:
Button* button;
if(context.systemName.equals("windows")) button = new ButtonWindows(context);
else if(context.systemName.equals("darwin")) button = new ButtonDarwin(context);
else if(context.systemName.equals("linux")) button = new ButtonLinux(context);
else throw std::runtime_error("Unsupported Platform");通过如上的抽象我们解决了更换操作系统时代码无法互用的问题,例如我们现在想要对于Linux发行版的Ubuntu 系统设置全新的按钮控件那么我们仅仅需要编写一个继承了Button 的类ButtonUbuntu 并且在应用实例时添加新的组合逻辑else-if语句即可。但是另一个问题似乎没有解决:我们还是无法将组合逻辑变更为纯粹的抽象——依赖关系仍然呈现出编译层面的高度耦合状况。这就要首先提到设计模式的一个重要概念了:依赖关系只能够转移而不能消解,设计模式解决的从来都是依赖关系的耦合程度而不是依赖关系本身。了解了这一点之后我们不妨思考一个问题:什么导致了组合逻辑位置的高度耦合性。
显而易见的,关键字new 导致了组合逻辑的强依赖,导致编译层面抽象接口无法与具体实现两部分之间达成高度解耦。这就引出了整个五类构造型设计模式的核心目标——通过代码手段构建一个具有多态特征的new 关键字的等效。那么我们可以引入一个”创建对象的类“的方式来构造这个具有多态特征的构造手段——工厂:
class ButtonFactory {
public:
virtual Button* getButton(const GraphicContext& context) = 0;
<template typename Args>
virtual Button* getButton(const GraphicContext& context,Args&& ...args) = 0;
virtual ~Button() = default;
};
//以ButtonLinux作为案例
class ButtonLinuxFactory : public ButtonFactory{
Button* getButton(const GraphicContext& context){
return new ButtonLinux(context);
}
<template typename Args>
Button* getButton(const GraphicContext& context,Args&& ...args){
return new ButtonLinux(context,std::forward<Args>(args));
}
};那么假设我们对以上所有按钮的子类都构建了对应的工厂子类,我们就说类ButtonFactory 是工厂(Factory)/创造器(Creator)而对应的返回子类实例的工厂子类是具体工厂(Concrete Factory)/实现创造器(Concrete Creator),而其返回的实例Button 或者其子类分别称为产品(Product)和具体产品(Concrete Product),这就是所谓的工厂模式。如果仅仅关心按钮那么这个位置看起来有些”过度设计“,但是我们如果考虑UI组件之中具有非常多的其他类型的组件,也就是工厂生产多种多样的产品,那么:
//定义各类产品接口和工厂接口
class Component {
public:
virtual void onDraw();
virtual ~Component() = default;
protected:
GraphicContext context;
};
class Button : public Component {
//codes
};
class TextView : public Component {
//codes
};
class EditText : public Component {
//codes
};
class ImageView : public Component {
//codes
};
class Slider : public Component {
//codes
};
class ComponentFactory {
public:
template<typename... Args>
virtual Button* getButton(const GraphicContext& context, Args&&... args);
template<typename... Args>
virtual TextView* getTextView(const GraphicContext& context, Args&&... args);
template<typename... Args>
virtual EditText* getEditText(const GraphicContext& context, Args&&... args);
template<typename... Args>
virtual ImageView* getImageView(const GraphicContext& context, Args&&... args);
template<typename... Args>
virtual Slider* getSlider(const GraphicContext& context, Args&&... args);
virtual ~ComponentFactory() = default;
};于是现在我们只需要实现对应平台的工厂和类的具体实现即可,例如对于MacOS平台:
class ButtonDarwin : public Button {
//codes
};
class TextViewDarwin : public TextView {
//codes
};
class EditTextDarwin : public EditText {
//codes
};
class ImageViewDarwin : public ImageView {
//codes
};
class SliderDarwin : public Slider {
//codes
};
class ComponentFactoryDarwin : public ComponentFactory {
template<typename... Args>
virtual Button* getButton(const GraphicContext& context, Args&&... args){
return new ButtonDarwin(context,std::forward<Args>(args));
}
template<typename... Args>
virtual TextView* getTextView(const GraphicContext& context, Args&&... args){
return new TextViewDarwin(context,std::forward<Args>(args));
}
template<typename... Args>
virtual EditText* getEditText(const GraphicContext& context, Args&&... args){
return new EditTextDarwin(context,std::forward<Args>(args));
}
template<typename... Args>
virtual ImageView* getImageView(const GraphicContext& context, Args&&... args){
return new ImageViewDarwin(context,std::forward<Args>(args));
}
template<typename... Args>
virtual Slider* getSlider(const GraphicContext& context, Args&&... args){
return new SliderDarwin(context,std::forward<Args>(args));
}
};这样即使是需要支持新的平台或者对于老的平台做出更加细分的更改,我们仅仅需要更改对应的具体产品实现和具体工厂实现即可,无需改动抽象产品和抽象工厂的既定代码,并且在使用中也可以分离工厂的选择和后续的使用:
//设定全局变量UI工厂,当然这里可以和单例模式组合使用
ComponentFactory* UI = nullptr;
//在主程序启动过程中设定工厂
int main(int argc, char** argv){
//other codes
if(context.systemName.equals("windows")) UI = new ComponentFactoryWindows();
else if(context.systemName.equals("darwin")) UI = new ComponentFactoryDarwin();
else if(context.systemName.equals("linux")) UI = new ComponentFactoryLinux();
else throw std::runtime_error("Unsupported Platform");
//other codes
}
//在后续任意位置通过设置好的工厂获取组件即可,因为多态特性,无需区分平台
UI->getButton(context);
UI->getTextView(context);
UI->getEditText(context);
UI->getImageView(context);
UI->getSlider(context);于是我们可以这样定义工厂模式使用的需求:
对象创建过程较为复杂:对象的创建设计复杂的初始化逻辑,例如依赖多个参数,需要根据环境进行不同的配置,与外部资源交互从而得到适合且多变的实例时,将创建逻辑封装在工厂之中实现多态特性的创建逻辑更加合理。
需要解耦实例化过程:如果客户端代码不宜依赖具体类或者需要进行代码分层,那么创建实例的过程应当依赖抽象接口,这样以来即使未来业务逻辑发生变化,高层代码也无需进行修改,从而应当设置工厂作为接口。
有运行时或者扩展可变性:如果软件设计的目标产品常常需要根据实际情况的变化扩展业务逻辑或者需要动态的根据运行环境决定创建不同类型的对象实例,那么使用工厂进行创建过程的多态化是有必要的。
那么简单的工厂方法模式的设计类图UML如下所示:
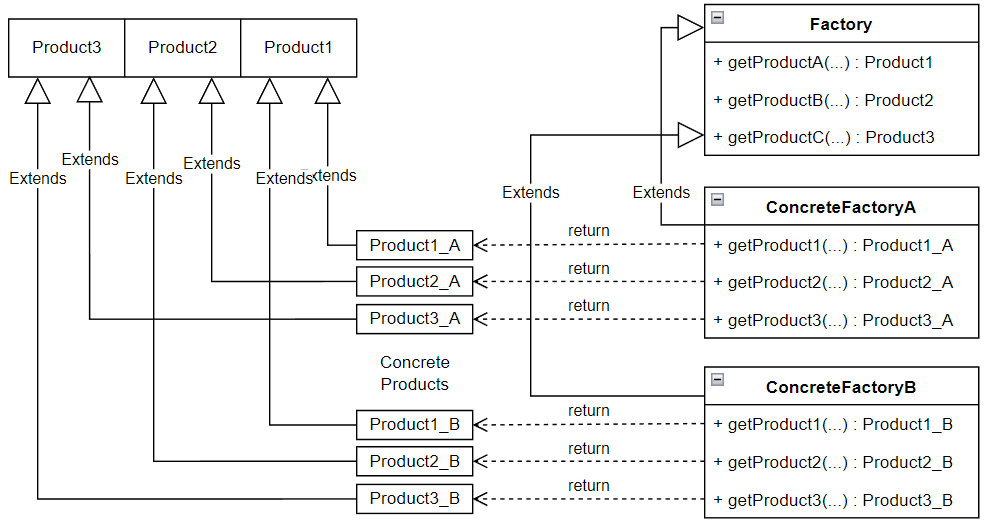
3.抽象工厂(Abstract Factory)模式
在上文的例子中,我们不难发现,构建UI组件库的时候,这些按钮、输入框、文本框都可以再度抽象:他们都是”组件“,都需要”绘制“也必然有共同的方法和属性,因此我们书写了一个Component 组件作为抽象但是并未将这个类具体投入使用。当我们使用工厂方法设计模式的时候本质上是构建一个仅仅含有实例化过程的类,使用虚函数的多态性质覆盖掉new 创建对象的强依赖性,那么什么情况下这些工厂方法可以再次进行更加高度的抽象或者组合呢?大概有以下两类情况:
多个产品在业务逻辑上属于一个超集的不同子集实例化,这种情况下这些产品应当继续抽象出一个抽象产品(Abstract Product)并且抽象出一个对应的工厂生产这些产品,使用抽象产品在代码之中代替产品从而获得更好的解耦多态特征和代码可复用性。
多个产品在业务逻辑上具有强关联性或者说绑定性,也就是说这些产品虽然对应不同的工厂,但是这些工厂必然同时出现或者同时按照某种使用条件进行具象实现,那么这个时候应当构建一个高级别的工厂组合这些强关联产品对应的工厂达到更好的集成度。
以上两种情况对应的解决方案虽然一个是抽象一个是组合,但是其殊途同归的特点是需要一个更加集成和抽象的“上级工厂”以管理直接生产产品的工厂,进而实例化时能够省去更多的操作,那么这个“上级工厂”就被我们称为是抽象工厂(Abstract Factory)。我们这里还是使用构建组件库的一个案例去分析抽象工厂的使用条件和应用范式:
这个组件库设计目标:
能够在不同平台(Platform)或者不同的图形绘制风格(Style)下运行
按钮类组件需要实现:点动按钮
PushButton,开关Switch,勾选框CheckBox文本类组件需要实现:标签
Label,文本区域TextView,文本输入框EditText,密码输入框Password,补全框Completion布局需要实现:固定布局
FixedLayout,线性布局LinearLayout,网格布局GridLayout,约束布局ConstraintLayout图形显示组件需要实现:图形
View,画布Canvas,图像ImageView
在这种情况下我们发现所有的组件不可能逃脱一些最基本的图形绘制约束:
该组件占据矩形的长宽、矩形左上角的二维坐标
该组件的绘制函数
该组件处于什么容器的内部
那么我们定义一个抽象产品基类表示任意组件的接口基类:
class Component {
protected:
Component* parent;
int x,y,width,height;
public:
int getPosX();
int getPosY();
int getWidth();
int getHeight();
void setPosition(const int x, const int y);
void setScale(const int width, const int height);
virtual void onDraw() = 0;
Component(const Component* parent = nullptr);
virtual ~Component() = default;
};对于容器类型的组件而言,构建一个容器类作为基类,容器本身也是一个组件那么这会引起菱形继承问题:如果一个组件继承了容器也继承了其他的组件基类那么最顶端的基类Component 究竟从谁继承?于是我们这样进行虚继承:
class Container : public virtual Component {
protected:
std::vector<Component*> children;
void drawChildren();
public:
void addChild(const Component* child);
int childrenCount();
Component* getChild(const int index);
};对于所有能够归纳为按钮的组件,我们抽象出一个二级抽象产品,最终产品继承它:
class Button : public virtual Component {
public:
enum Status{
ButtonIdle = 0x00,
ButtonHovered,
ButtonPushed,
ButtonChecked
};
protected:
Button::Status state;
public:
void onClick();
void onPushed();
void onReleased();
void onHovered();
};
class PushButton : public Button { /* implementation codes */ };
class Switch : public Button { /* implementation codes */ };
class CheckBox: public Button { /* implementation codes */ };同样的对于所有文本类的组件,我们首先抽象出一个二级抽象产品,这个产品细分为一些非编辑特征的最终产品,而后用一个三级产品抽象所有可编辑产品:
class Text : public virtual Component {
protected:
std::string text;
public:
std::string getText();
void setText(const std::string& text);
};
class Label : public Text { /* implementation codes */ };
class TextView : public Text { /* implementation codes */ };
class EditText : public Text {
public:
void onEdit(const Event& event, const std::string& afterEdit);
};
class Password : public EditText { /* implementation codes */ };
class Completion : public EditText { /* implementation codes */ };对于图形组件而言,如同按钮组件一样如法炮制即可,只不过二级产品不是纯粹的抽象产品而是一个可以实例化的有意义的最终产品,但是同时也是抽象产品;而画布组件可能包含其他的图形并且不能直接合并需要分图层独立管理,那么可以使用多重继承的方式既是一个图形子类也是一个容器:
class View : public virtual Component {
protected:
Image image;
public:
Image getImage();
void setImage(const Image& image);
};
class Canvas : public View, public Container { /* implementation codes */ };
class ImageView: public View { /* implementation codes */ };最后对于布局类组件,他们是纯粹的容器,抽象出一个最基础的二级产品即可,此处不从容器直接继承是因为后续可能加入其他的容器,需要保证抽象的合理性,并且布局必须要依赖于其他的容器存在,如果没有容器何谈布局:
class Layout : public Container {};
class LinearLayout : public Layout { /* implementation codes */ };
class ConstraintLayout : public Layout { /* implementation codes */ };
class GridLayout : public Layout { /* implementation codes */ };完成后所有产品的继承关系为:
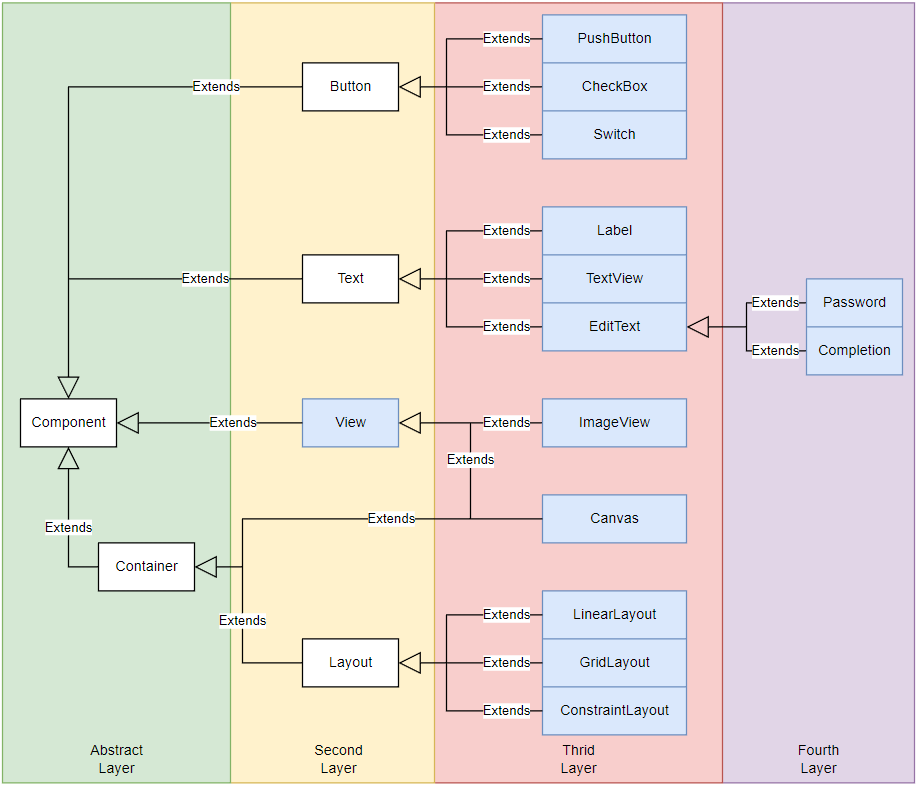
接下来构造对应的工厂,根据各个层级自顶向下构建抽象工厂,构建抽象工厂的方式和级别根据不同的代码需求有所不同,例如如果我们只想要取得二层抽象级别的工厂那么可以这样书写:
class AbstractComponentFactory {
public:
virtual Button* createButton() = 0;
virtual Text* createText() = 0;
virtual Layout* createLayout() = 0;
virtual View* createView() = 0;
virtual ~AbstractComponentFactory() = default;
};而如果想要展开到三层抽象级别的工厂可以进行抽象工厂的组合和嵌套:
class AbstractButtonFactory {
public:
virtual PushButton* createPushButton() = 0;
virtual Switch* createSwitch() = 0;
virtual CheckBox* createCheckBox() = 0;
virtual ~AbstractComponentFactory() = default;
};
class AbstractTextFactory {
public:
virtual Label* createLabel() = 0;
virtual TextView* createTextView() = 0;
virtual EditText* createEditText() = 0;
virtual ~AbstractTextFactory() = default;
};
class AbstractViewFactory{
public:
virtual Canvas* createCanvas() = 0;
virtual ImageView* createImageView() = 0;
virtual ~AbstractViewFactory() = default;
};
class AbstractLayoutFactory{
public:
virtual LinearLayout* createLinearLayout() = 0;
virtual ConstraintLayout* createConstraintLayout() = 0;
virtual GridLayout* createGridLayout() = 0;
virtual ~AbstractLayoutFactory() = default;
};
class ComponentFactory {
public:
const AbstractButtonFactory* buttonCreator;
const AbstractTextFactory* textCreator;
const AbstractViewFactory* viewCreator;
const AbstractLayoutFactory* layoutCreator;
virtual View* createView() = 0;
ComponentFactory(AbstractButtonFactory*,AbstractTextFactory*,AbstractViewFactory*,AbstractLayoutFactory*);
~ComponentFactory()
};假设我们在不同的平台例如Windows和MacOS下分别需要实现这些组件并且根据操作系统的不同使用不同的图形渲染手段和图形美学设计风格,那么我们不需要关注含有组合逻辑的上级工厂,我们可以直接实例化这些工厂类而含有虚函数也就是工厂方法的抽象工厂需要我们书写一个类去继承它并且附加对应平台的实现方法,这样就将零敲碎打或者沆瀣一气的工厂方法模式进行了分级分层和更彻底的抽象,能够更好的提高代码复用率并且降低耦合性。
也就是说,在抽象工厂(Abstract Factory)之中既可以直接在顶层展开工厂方法(Factory Method)接驳一般工厂模式,也可以根据抽象程度先通过HAS-A模式也就是成员变量的模式组合下级抽象工厂,而后在下级抽象工厂之中转入工厂方法阶段。抽象工厂提供了一种针对多层多联系的产品进行高度抽象的思考方法,然而其应用手段灵活多变,切记不可以教条的使用。总的来说,当以下情况出现时一般需要将普通的工厂方法模式部分变更为抽象工厂模式:
需要创建一组相关或者相互依赖或者具有共同抽象的产品
产品划分为不同产品族并且产品族内需要保证各个产品一致性
避免客户端与具体的类耦合,并且避免客户端随意的组合多个工厂
典型的抽象工厂的UML类图可以这样进行总结:
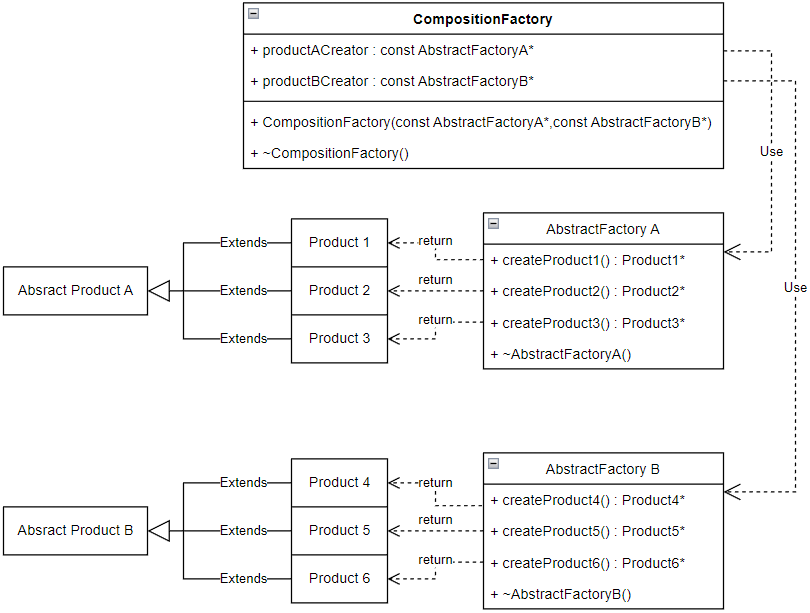
4.原型(Prototype)模式
在了解了工厂模式的设计目的、具体实现方法和抽象之后,这看起来是一个万全的方法:可以构造一个具有多态特征的实例化过程,并且绑定到面向对象语法之中,一切的对象抽象为产品并且根据他们之间的组合和依赖关系进行分层划分出抽象工厂……然而在面对实际业务的时候我们很多时候在做一件事情:从时间和步骤尺度上将实例化过程和实例使用过程分割,即使我们不使用面向对象编程,这是为什么呢?我们发现任何一种数据结构(实例)的创建和使用或多或少具有这两个划分或者说这两个特征:
实例数据的预备阶段,或者说实例化阶段。在这个阶段之中我们也许需要预填充数据以获得初始状态,又或者加载什么库或者配置文件以便后续的使用,这个过程的总特征是:可能包含非常具有时间复杂度和空间复杂的的算法,大量占用执行平台计算资源但是对于单个实例来说在生命周期之中仅仅出现一次,是调用频率低复杂度高得过程。
实例数据的使用阶段,或者说具体业务阶段。在这个阶段之中我们通过调用各种对象的成员方法或者类本身的静态方法,甚至直接修改类成员数据(当然这不推荐,这也是所谓的“屎山代码”病灶)以达成业务逻辑的具体实现。通常来说在这个部分之中我们会通过任务划分步骤切割或者单一重要算法优化的手段使得时空复杂度大大降低。这个过程的总特征是:对于若干个抽象化的经过优化的复杂度较低的具体实现高频次调用,重复实现业务逻辑的运行。
看起来这个方针毫无问题并且能够使用工厂方法模式或者抽象工厂模式迅速解决问题,但是存在这样一种可能性:由于业务容量的扩大或者对应业务种类本身的特性导致在实例数据的预备阶段出现了高频次调用的现象。那么这个时候该阶段的美好性质就荡然无存:一份高复杂度的代码被高频率使用一定会导致系统资源的迅速占用和无法快速释放的现象出现。那么假设我们已经无法通过优化算法或者分解业务类型的方式获得建设性的效果拔群的手段,我们该如何应对?
事实上这个思想在各个自然科学领域,尤其是计算科学和软件工程领域总是出现:当我们有某种成功的范式,我们仅需要确认使用条件恰当,那么任何使得问题变得复杂的变例都可以通过“将新问题转化为旧问题”去重复使用成功的范式以轻松解决问题。那么上文之中提及的两个阶段思想的应用条件是什么呢——在第二阶段之中与第一阶段没有太大的耦合性,其仅仅使用第一阶段的结果并且这个结果不具有数据层面的唯一性,也就是说可替换。那么我们非常自然的想法就是:如果需要不停的进行复杂的实例化过程,为什么我们不再次分割第一阶段:
小阶段A:将对应需求的实例数据(包括初始状态,加载库或者配置文件之类的)进行正常的实例化过程,但是我们人为控制这个过程不会被重复调用,仅仅在获取该类型数据的时候进行一次性的加载。在本阶段之中创造出来的实例数据唯一的使用方法就是产生其他的和该实例对象相像或者完全相同的其他实例。
小阶段B:将对于实例化过程高频调用的接口转移到此处,我们在这个部分之中将实例化过程看作是小阶段A过程的一种“实例数据使用”即可,也就是对阶段A构成的具有初始化特征的实例数据进行简单的变更或者干脆复制得到我们想要的目标。这样以来高复杂度又高频调用的实例创建过程通过本阶段的接口就可以将高复杂度特征和高频调用特征解耦。
在小阶段A之中创建出来用于重复创造实例的实例对象就被我们称为原型(Prototype),这种设计模式就被称为原型模式。事实上这种思想在人类的科技发展历史之中经常出现:当我们传播信息和知识的时候我们发明了书籍,在这个过程之中实际上已经进行了两个阶段的分割:编撰书籍的过程就是实例化的过程,这个过程耗费时间金钱精力巨大,但是一旦书籍编撰成功,那么针对于每个阅读此书籍的个体而言,信息和知识能否成功传递仅仅在于阅读者的理解能力和阅读时间。然而当我们要将这种知识“广而告之”的时候显然一本书是不够用的——因此我们需要复制这些书籍,但是手抄书籍就是高频次高复杂度的实例化过程,因此我们发明了印刷术。在雕版印刷的年代之中,编撰书籍的原本不会直接发行而是通过工匠雕刻出雕版随后雕版印刷出其他的复制版本发行,这就是一种原型模式!当然,在漫长的印刷技术发展过程中我们发现制作雕版还是过于复杂和昂贵,因此我们使用活字印刷术——这实际上是一种原型模式和抽象工厂模式的结合!每个活字字符都是一个“字模“抽象产品的子类实例也就是具象产品,而这些具象产品又构成了原型模式进行”复制“动作的手段。
那么要使用原型模式,我们不妨来看下面这样一个具体的实际业务之中经常出现的例子:
假设我们有一个系统需要处理大量类似的配置对象,这些对象包含一组复杂的属性。每次初始化这些配置对象都需要读取文件、解析并加载到内存中。而且这种配置对象可以根据种类区分出不同的”初始模板“,例如基础配置的
basic模板,高级配置的advanced模板等等,我们需要为上级代码提供一份”默认配置“,而上级代码决定通过这些默认配置进行何种细节上的更改。
首先定义一个Config 基类作为所有类型的配置对象的抽象存在,其中使用到了原型模式之中最为核心的一个方法clone() 并且将其定义为一个虚方法接口,后续除了原型对象实例本身,其他的实例应当通过该原型克隆得到:
class Config {
public:
virtual Config* clone() const = 0;
virtual ~Config() = default;
//other codes
protected:
std::string name;
int verMajor;
int verMinor;
int verPatch;
File file;
//other codes
};对于不同类型的配置对象书写不同的子类并且实现核心方法clone() ,注意这个函数必须是一个深拷贝方法而不能是一个浅拷贝实现,否则其中的指针数据会被解析到原型对象实例本身而不是被克隆后的对象实例上,并且作为克隆模板的原型对象实例绝对不能投入实际业务逻辑的使用,否则这个实例对象将会偏离我们既定设想的初始化状态而被其他业务逻辑污染:
class BasicConfig : public Config {
public:
Config* clone() {
// deep copy implementation for BasicConfig
}
//other codes
};
class AdvancedConfig : public Config {
public:
Config* clone() {
// deep copy implementation for AdvancedConfig
}
//other codes
};
//在创建配置模板阶段:
BasicConfig* basicConfigPrototype = new BasicConfig();
AdvancedConfig* basicConfigPrototype = new AdvancedConfig();
//后续使用配置原型克隆对象即可,例如设定一个函数用于获取
Config* getConfigObject(Config* configPrototype){
return configPrototype->clone();
}
auto anotherBasicConfig = dynamic_cast<BasicConfig*>(getConfigObject(basicConfigPrototype));
auto anotherAdvancedConfig = dynamic_cast<AdvancedConfig*>(getConfigObject(advancedConfigPrototype));或者我们甚至可以增添一个辅助的单例类管理已经创建的所有原型实例并且通过一个Map管理他们:
class Config {
protected:
std::string name;
int verMajor;
int verMinor;
int verPatch;
std::string filePath;
public:
Config(const std::string& name, const std::string& path, const int verMajor, const int verMinor = 0, const int verPatch = 0);
virtual ~Config() = default;
virtual std::unique<ptr> clone();
//other codes
};
class ConfigRegisty : public Singleton<ConfigRegistry> {
private:
std::unordered_map<std::string, std::unique_ptr<Config>> prototypes;
ConfigRegistry() = default;
public:
friend class Singleton;
void registerConfig(const std::string& key, std::unique_ptr<Config> config){
prototypes[key] = std::move(config);
}
void unregisterConfig(const std::string& key){
prototypes.erase(key);
}
std::optional<std::unique_ptr<Config>> getConfig(const std::string& key) const {
auto it = prototypes.find(key);
if(it != prototypes.end()) return it->second->clone();
return std::nullopt;
}
};
class BasicConfig : public Config {
public:
Config* clone() {
// deep copy implementation for BasicConfig
}
//other codes
};
class AdvancedConfig : public Config {
public:
Config* clone() {
// deep copy implementation for AdvancedConfig
}
//other codes
};
//首先初始化Config仓库单例
std::shared_ptr<ConfigRegisty> registry = ConfigRegisty::getInstance();
//注册原型
registry.registerConfig("basic",
std::make_unique<BasicConfig>("Basic Configuration","/etc/basicConfig.json",1));
registry.registerConfig("advance old",
std::make_unique<AdvancedConfig>("Advance Ver.1","/etc/advance1Config.json",1));
registry.registerConfig("advance new",
std::make_unique<AdvancedConfig>("Advance Ver.2","/etc/advance2Config.json",2));
registry.registerConfig("advance patch",
std::make_unique<AdvancedConfig>("Advance Ver.201","/etc/advance2ConfigPatch.json",2,0,1));
//使用原型
auto newBasicConfig = registry.getConfig("basic");
auto newAdvanceConfig = registry.getConfig("advance patch");总的来说,原型模式在实际的业务逻辑之中的使用频繁程度不如工厂模式多,而且使用时通常需要搭配单例模式构建原型仓库或者搭配工厂模式完成多原型的初始化工作,一般来说在如下情况出现时经常使用原型模式融合在实例化过程之中:
对象创建成本高:对象的初始化非常复杂,例如依赖外部资源、网络请求或者具有复杂逻辑,直接克隆现有对象可以显著减少资源消耗开销。并且对象的创建动作频繁复用,此时工程模式需要为每个对象单独实现实例化逻辑,而原型模式可以通过既有初始化对象快速生成。
大量相似对象的创建:当需要创建多个具有相似但是不同值属性的对象,也就是归纳为同一子类的不同实例化对象时,克隆现有对象比重新实例化更加高效。并且工厂模式的多态特征和变化对抗特性出现于子类多态层面,但是原型模式可以做到同一子类原型克隆后的不同属性取值的配置。
对象属性动态调整:如同上一条所述,如果需要在运行时动态修改某个属性值但是不需要对其定义(原型)进行修改时,工厂模式在此类问题上乏力然而原型模式结合简单的具体实现代码可以达成效果拔群的运行时动态。
对于业务运行代码的高性能要求:原型模式的本质实际上是对实例化过程进行了二次类似”初始化-使用态“的划分,这样就能够将复杂的、效率低下的初始化过程二次切割出来,保证后续频繁调用的代码与这些高资源开销代码相分离从而提高高频调用代码整体的性能以塑造良好的用户体验。
在使用原型模式时通常需要遵守或者常见这样几样特点:
基于克隆构建实例化过程:原型模式的核心是通过实现一个虚函数表中的
clone()方法构建一个具有多态特征的实例化过程,因此无论原型模式如何变更或者与其他设计模式如何搭配,其显著特点是实现了这个克隆方法。需要具体实现对象深拷贝:一般来说原型实例是不应当或者说禁止投入具体业务逻辑的使用的,那么在克隆原型生产新实例的时候就一定要考虑到对象的深拷贝问题,否则可能导致意料之外的业务逻辑代码通过浅拷贝漏洞污染原型实例。在整个原型模式的使用中原型实例本身的纯洁性和新实例的可用性依赖于深拷贝实现。
通常结合注册表实现:如果在一个系统之中出现了同一个类或者同一个类多个子类下的多种原型实例用于创建不同的新实例的情况,一般来说为了良好的管理和复用原型对象需要构建一个注册表类,这个类通常使用单例模式或者抽象工厂模式。
最后通过原型模式的UML类图进行一个总结:
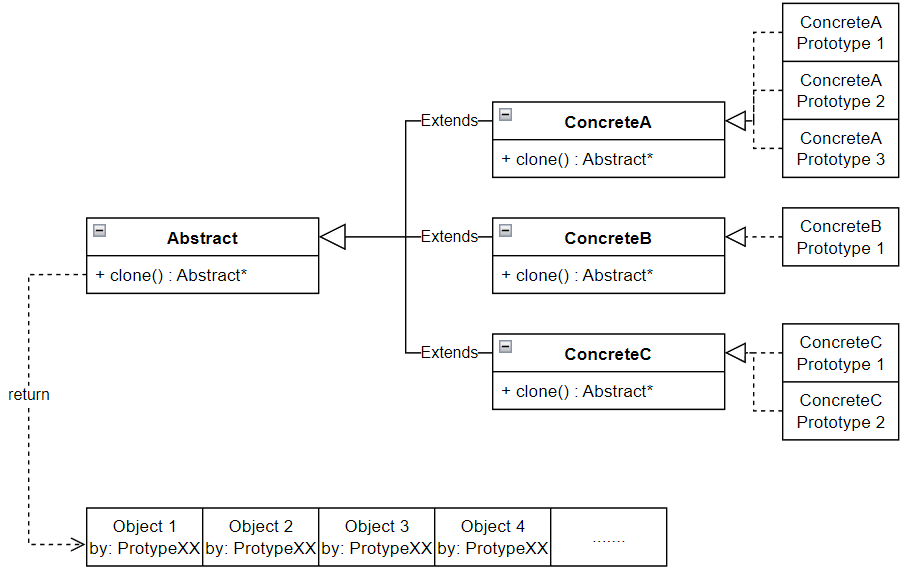
5.构造器(Builder)模式
回顾我们已经涉猎的三类创建型设计模式,我们的核心是构建一个具有多态特征的实例化过程,并且根据我们面对的不同使用场景使用多种手段提高复用性和降低耦合性,然而在这其中我们始终无法避开或者说一直在通过设计模式转移但是无法消解的复杂度是什么?其实通过设计模式消解掉多变特征之后剩下的复杂性本身就是创建实例过程整个流程逻辑的复杂性。而一般来说这样的基于流程的复杂性总是能够通过流程本身的切割实现进一步的简化和复用,这其实也是一种哲学思想:”毒蛇栖息之地,七步之内必有解药“——如果我们坚信宇宙的规律是均匀和均一的,那么当我们发现了某件事情的复杂性大大超出了平均程度时那么产生/消解这种复杂性的原理/手段也必然伴生出现从而维持整体-局部上规律和特性的均匀性。我们使用这样一个例子来解释这种基于流程的复杂度可分解的特征:
假设我们目前为PC DIY爱好者创建了一个DIY装机平台,这个平台的核心作用之一是根据选定的硬件种类的不同构建出一个DIY PC装机方案并且给出一份包括成本、功耗、兼容性的报告提交到用户供其进行综合评估,为了完成这一目标我们就需要对一台计算机的各个部件进行设置从而最后得出结论,我们可能涉及的部件有:
中央处理器
CPU运行内存
RAM主板
MotherBoard存储
Storage电源
PowerSupply图形处理器
GPU网络适配器
NetworkAdapter声音适配器
SoundAdapter机箱
Case散热器
Radiator
显然,这是一个非常复杂的任务,当我们选定了硬件之后自然可以通过系统之中其他部分的API查找出对应的兼容性问题、功耗需求、成本需求等等,但是类Computer 的构建工作和流程一定是一串又臭又长的糟糕代码逻辑,并且随着DIY模式的不同例如以游戏为目的设计的方案肯定优先考虑GPU和CPU的L3缓存,但是以NAS为设计目标的方案肯定优先考虑存储空间和主板对于HBA等扩展卡的支持以及如果要7x24运行必须涉及的功耗考量……那么我们可以对这个工作进行一些基本的分解:
class Computer {
protected:
std::vector<CPU> cpu;
std::vector<RAM> ram;
std::vector<Storage> storage;
MotherBoard motherboard;
PowerSupply power;
Case chasis;
std::vector<Radiator> radiators;
std::vector<Extension> extensionCards;
public:
virtual bool addCPU(const CPU& cpu) = 0;
virtual bool removeCPU(const int index) = 0;
const std::vector<CPU>& getCPU();
virtual bool addRAM(const RAM& ram) = 0;
virtual bool removeRAM(const int index) = 0;
const std::vector<RAM>& getRAM();
virtual bool addStorage(const Storage& storage) = 0;
virtual bool removeStorage(const int index) = 0;
const std::vector<Storage> getStorage();
virtual bool setMotherBoard(const MotherBoard& motherboard) = 0;
const MotherBoard& getMotherBoard();
virtual bool setPowerSupply(const PowerSupply& power) = 0;
const PowerSupply& getPowerSupply();
virtual bool setCase(const Case& chasis) = 0;
const Case& getCase();
virtual bool addRadiator(const Radiator& radiator) = 0;
virtual bool removeRadiator(const int index) = 0;
const std::vector<Radiator>& getRadiators();
virtual bool addExtension(const Extension extension) = 0;
virtual bool removeExtension(const int index) = 0;
const std::vector<Extension>& getExtensions();
virtual const double calculatePower() = 0;
virtual const double calculateBudget() = 0;
virtual const double calculateStorage() = 0;
virtual const double calculateRAM() = 0;
virtual const std::vector<Issue>& checkCompatibility();
virtual ~Computer() =default;
};这样以来,我们就不必要在构造器之中实现所有的参数填充和成员装配任务——如果必须要实现一个这样的构造器可以想见的是这个构造函数将会如同一个肿瘤一样毁掉整个代码。那么针对于这样的一个基类假设我们实现了这样的一个子类,我们可以通过这样的方式将构造实例化过程分解开来:
class MyComputer : public Computer{
//implementation
};
auto computer = new MyComputer();
computer->addCPU(CpuRegistry.get("AMD Ryzen9 9950X"));
computer->setMotherBoard(MotherBoardRegistry.get("AsRock B650"));
computer->addRAM(RamRegistry.get("SAMSUNG DDR5 32GB 5600"));
computer->addRAM(RamRegistry.get("SAMSUNG DDR5 32GB 5600"));
computer->setPowerSupply(PowerRegistry.get("SilverStone 850W"));
computer->setCase(CasRegistry.get("SilverStone CS382"));
computer->addStorage(StorageRegistry.get("WD SN 850"));
computer->addStorage(StorageRegistry.get("Seagate 710E"));
computer->addStorage(StorageRegistry.get("Seagate 710E"));
computer->addRadiator(RadiatorRegistry.get("Custom Thermal Cooler"));
computer->addExtension(ExtensionRegistry.getGPU("Nvidia RTX4080"));看到这里有些朋友可能有自己的疑惑:我们是否可以通过制造一个中间类或者结构体例如ComputerConfig 来存储这些标志着各种配件的筛选条件,然后通过在构造函数之中传入这个结构体或者中间类的实例,然后在构造器之中调用这些setter函数呢?那么这里就要提到C++的类实例实现机制了:我们用类MyComputer 或者其他的什么子类具体实现了虚基类Computer 并且为了利用多态性质这些setter都是虚函数位于虚函数表vTable之中。这个虚函数表的是”延迟绑定“的,也就是这些函数与类之间的绑定发生在实例构造完成之后,那么我们在构造器之中调用这些虚函数表之中尚未绑定的具体实现函数就会引发错误。如果您使用Java或者其他什么面向对象编程的语言去这样做在语法上当然是可以的,但是这在逻辑上讲不通:当一个实例尚未构造完毕的时候调用其使用阶段的函数是矛盾的。
然而正是因为这种讲不通,我们发现将实例化过程依赖运行阶段去实现会引发一些问题:当我们执行了默认的构造器时实际上对应的配件字段并未初始化,处于未定义状态,这个时候如果直接调用其他函数就会引起运行时错误或者业务逻辑的错误。如果我们要求客户端代码使用这份代码时必须遵守我们的”构造分步骤“逻辑那么显然违反了设计原则——将用户不必要的动作和责任强加给上级代码引入了多余的耦合性!为了解决这个问题就要提到本小节的核心——构造器(Builder)模式,我们需要这样的一个Builder类:
class ComputerBuilder {
public:
virtual ~ComputerBuilder() = default;
virtual Computer* build();
};
class MyComputerBuilder : public ComputerBuilder {
public:
Computer* build() override {
auto computer = new MyComputer();
computer->addCPU(CpuRegistry.get("AMD Ryzen9 9950X"));
computer->setMotherBoard(MotherBoardRegistry.get("AsRock B650"));
computer->addRAM(RamRegistry.get("SAMSUNG DDR5 32GB 5600"));
computer->addRAM(RamRegistry.get("SAMSUNG DDR5 32GB 5600"));
computer->setPowerSupply(PowerRegistry.get("SilverStone 850W"));
computer->setCase(CasRegistry.get("SilverStone CS382"));
computer->addStorage(StorageRegistry.get("WD SN 850"));
computer->addStorage(StorageRegistry.get("Seagate 710E"));
computer->addStorage(StorageRegistry.get("Seagate 710E"));
computer->addRadiator(RadiatorRegistry.get("Custom Thermal Cooler"));
computer->addExtension(ExtensionRegistry.getGPU("Nvidia RTX4080"));
return computer;
}
};这样以来就避免了用户负担额外的构造逻辑引入实例化过程耦合性和额外依赖的问题,用户仅需要执行builder->build()即可获得期望的构建完成的对象投入使用。以上代码之中为了举例的便捷性直接将配件的细节实现到代码之中,实际上应当在Builder类之中抽象出设定各个配件的函数,然后根据用户代码的定义去构建这个实例,例如:
class Computer ComputerBuilder {
public:
struct HardwareList {
//implementation detail
}
virtual setCPU() = 0;
virtual setRAM() = 0;
//other hardware setter
ComputerBuilder(const ComputerBuilder::HardwareList& requirement);
virtual ~ComputerBuilder() = default;
virtual Computer* build();
protected:
ComputerBuiler::HardwareList detail;
};那么用户在使用这种构造器模式的代码的时候只需要预先设定好一个硬件列表结构体Computer::HardwareList 的实例然后将其装填入Builder子类的构造器后调用build() 函数,在该函数内部将会使用Builder的其他函数获取对应的硬件字段装填Computer实例返回给用户代码。然而我们又发现一个问题:在这个例子包括现实业务逻辑之中构造实例的过程不仅仅需要分步骤,有的时候步骤不具有可交换性或者说根据不同的实例用途步骤的顺序需要发生更改。
例如:当我们装配一台游戏电脑时我们希望优先考虑CPU+GPU的性能再考虑散热器的可行性,随后考虑内存容量和速度和配置SSD存储,最后考虑的才是HDD硬盘和机箱,在这个过程之中如果我们首先选择了CPU+主板但是主板由于芯片组性能无法装配我们需要的GPU那么就出现了业务逻辑问题。又或者我们的设计目标是NAS,那么GPU基本上根本不需要考虑,反而优先考虑的是主板是否有足够的SATA/PCIE通道用于连接大量的HDD硬盘……所以问题就出现在方法build() 上,于是本着一贯的原则,我们需要对这个过程进行二次抽象,引入一个构造器指挥者Director 类具体实现不同目的的装配流程:
class ComputerBuilder {
public:
struct HardwareList {
//implementation detail
};
virtual bool setCPU() = 0;
virtual bool setRAM() = 0;
//other hardware setter
ComputerBuilder(const ComputerBuilder::HardwareList& requirement);
virtual ~ComputerBuilder() = default;
Computer* getResult();
protected:
ComputerBuiler::HardwareList detail;
Computer* target;
};
class ComputerBuildDirector {
public:
ComputerBuildDirector(const ComputerBuilder* builder);
ComputerBuilder* getBuilder();
virtual const std::vector<Issue>& construct() = 0;
virtual ~ComputerBuildDirector() = default;
private:
ComputerBuilder* builder;
};对于以上的代码在具体实现的时候需要这样使用:
//首先实现对应的Computer子类
class GamingComputer : public Computer {
//implementation codes
}
//对于Computer子类实现对应的Builder子类
class GamingComputerBuilder : public ComputerBuilder {
//implementation codes
}
//一个Builder可以搭配不同的Director子类实现顺序和步骤的多种策略
class GrahpicPiorityDirector : public ComputerBuildDirector {
//implementation codes
}
class MemoryPiorityDirector : public ComputerBuildDirector {
//implementation codes
}
//在具体使用的客户端代码之中使用多态特性
std::vector<Computer*> getComputers(const std::vector<ComputerBuildDirector*> directors){
std::vector<Computer*> result;
for(size_t i=0;i<directors.size();i++){
if(direcotrs[i]->construct().empty())
result.push_back(directors[i]->getBuilder()->getResult());
}
return result;
}当然在实际应用设计模式的过程之中不一定非要加入Director 类,当构建流程足够固定而清晰的时候应当省略不必要的中间类,甚至说当构建过程是固定的流程但是并不具有多变特征不会引起代码复用率降低的情况下构造器模式本身都可以省略,一定要注意过度设计的问题,我们的核心是得到干净高效的可执行代码而不是非要应用模式,切忌本末倒置。此处需要补充一点,非常多的构造器模式可能采用链式调用的方法,例如:
class ComputerBuilder {
public:
struct HardwareList {
//implementation detail
};
//修改了返回值类型
virtual ComputerBuilder* setCPU() = 0;
virtual ComputerBuilder* setRAM() = 0;
//other hardware setter
ComputerBuilder(const ComputerBuilder::HardwareList& requirement);
virtual ~ComputerBuilder() = default;
Computer* getResult();
protected:
ComputerBuiler::HardwareList detail;
Computer* target;
};
//子类实现
class MyComputerBuilder : public ComputerBuilder {
//implementation codes
};
//链式调用:
auto builder = new ComputerBuilder();
auto computer = builder->setCPU()->setRAM()->getResult();总的来说当以下条件出现时需要使用构造器模式:
实例化过程复杂且可分解:当一个对象的创建流程非常复杂,并且创建结果并不能和原型模式的情况一样直接复制初始化状态使用时,我们应当试图分解创建流程为几个步骤,如果能够做到这一点就可以使用构建器模式。
同一构建过程生成多变的结果:如果需要根据不同的配置、需求或者策略创建具有相同大致结构但是具体结构细节或者属性取值不同的对象时考虑使用构建器模式,这样可以大大提高代码的复用性。
需要优化构造函数:当一个对象的构造函数参数过多或者嵌套逻辑过于复杂的时候,使用构造器模式可以大大提高代码的可读性和可维护性。并且作为创建型设计模式,构造器模式本身的特性之一就是能够分离实例化过程并提供多态特征。
构建器(Builder)模式的UML类图可以总结为:
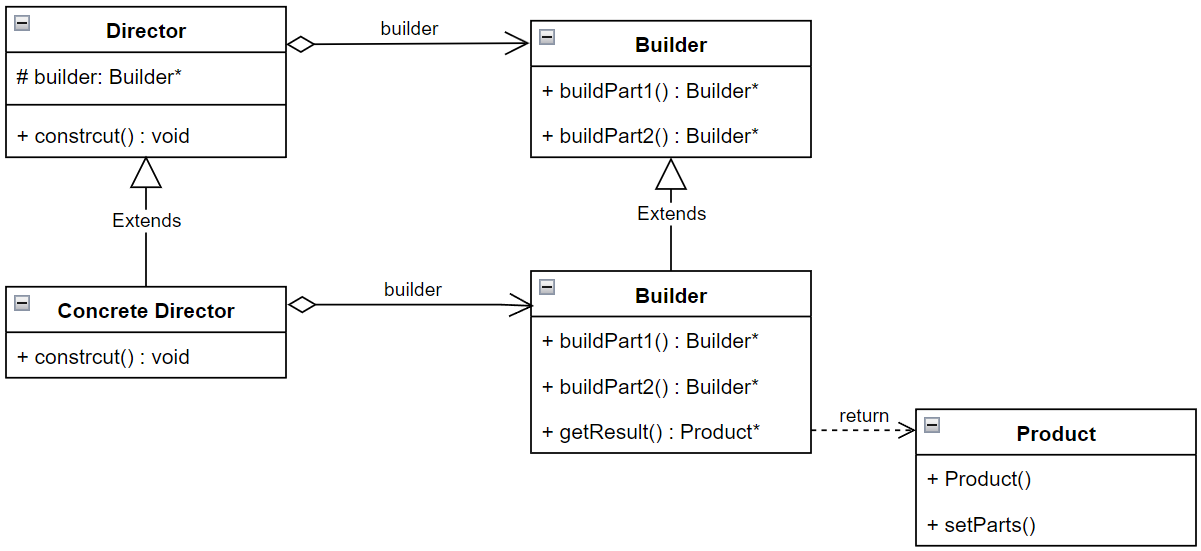
6.总结
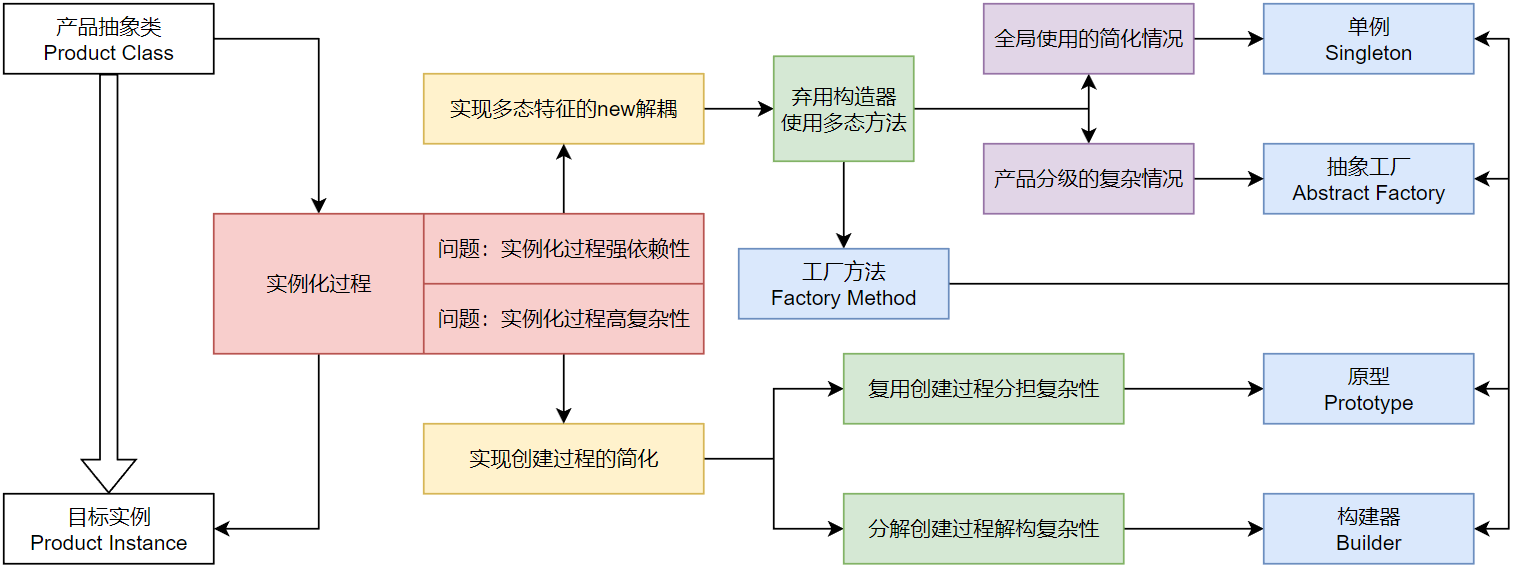
如上图所示:本文提到的五种创建类的设计模式关心的就是从抽象的产品的类的定义实例化为可以运行业务逻辑目标的过程,而具体的实现业务逻辑的实例使用过程不属于创建型设计模式的考虑范畴。在这个过程之中影响代码复用率和提供高度耦合性以及复杂性的根源主要有两个部分构成,也为我们的设计模式提供了目标:
实例化过程依赖于
new关键字和构造函数,因而具有强依赖性,无法使用面向对象的多态特征进行解耦实例化过程有时的参数和逻辑过于复杂,大大影响了代码的执行效率,必须优化这一过程的实现逻辑范式
解决这两个问题的方法是迥异的但是核心手段是相同的:使用一个函数代替new 关键字并且让这个函数实现”延迟绑定“即利用虚函数表的特征将其多态化处理,这个代替性的函数或者说方法就被称为工厂方法(Factory Method)也就是我们第二小节谈到的设计模式。基于这种思考方式和设计模式对两方面的问题再次进行分类:
针对工厂方法的使用过程可以根据产品的种类和使用范围按照复杂性进行分类:
对于全局使用的或者说需要并且能够进行数据流动精细控制的简化场景,我们放弃工厂类
Factory而直接将这个方法静态化处理,也就是变例为单例模式(Singleton)之中的核心方法getInstance()可以看作将产品类变为自带工厂方法的简化方案。对于产品种类繁多或者相互联系的复杂情况,对产品进行二次抽象和组合,同样的也需要对各级别的工厂类进行二次抽象或者组合,根据展开等级的不同划分出抽象工厂
Abstract Factory和具体工厂Concrete Factory这就是抽象工厂模式(Abstract Factory)。
针对工厂方法本身的复杂性,即实例创建过程的搞复杂性的优化方案有两种思考方式:
如果能够复用创建过程本身,相当于在多次创建动作之中分担了复杂性,平均来看每次创建的复杂性大大降低。核心即复用也就是按照固定的范式进行克隆
clone(),将工厂方法转变为按照指定实例克隆的这种手段就称为原型模式(Prototype)。如果能够分解创建过程本身,也就是将复杂性进行解构,本质是通过组合-抽象的方法解耦和复用了创建过程的不同部分,那么我们就要引入抽象-组合本过程的一个新的抽象类
Builder并且可能需要搭配对应的策略类Director,这样就是构造器模式(Builder)。